oracle分页技术性能比较
一、前言
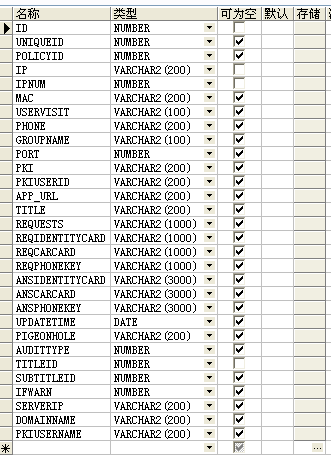
在一个有30亿条数据的大表上分页,为了对方案进行性能测试,先忽略其他条件查询的影响,单看下分页部分的性能,顺便考察说明下oracle中rownum使用中一些比较tricky的地方。 实验条件: 表结构如下,内有2千万条实验数据。
二、实验
提供7种不同方式(其实是5种,二和四是一种、三和五是一种)方式的 。第一种只是为了demo一下假设的一种错误逻辑方式,第二种和第四种是一种逻辑正确,但是性能极差的方式。筛选下来看上去性能可行的方式是第五、第六、第七方式。 这里仅仅记录没中方式的执行结果和计划。
方式1
笨笨的想想。Oracle里面不是有个变量叫rownum,顾名思义,就是行号的意思,我要获取第十行到第二十行的数据,sql写起来很精练!比myslq的limit和mssql的top折腾看着还要优雅!
1select * from idouba.APP_CLUSTEREDAUDITLOG where rownum between 10 and 20
喔!十条记录执行了十分钟还么有结果,一定是哪儿有问题了,shut了重试。那就来个简单的:
1select * from idouba.APP_CLUSTEREDAUDITLOG where rownum =10
也没有记录,再尝试rownum=2都不会有记录。 分析rownum的原理就不难理解。rownum是查询到的结果集中的一个伪列,可以理解成在我们查询到的结果上加序号。按照这个逻辑,写rownum=1是能得到结果集的第一行。执行rownum=2时,先比较第一行,其rownum是1,则扔掉,考察下一行,rownum又是1,直到扫描完整个表,没有满足条件的结果集。 查询计划如下。
已用时间: 00: 04: 01.81
1执行计划
2----------------------------------------------------------
3Plan hash value: 2858290634
4--------------------------------------------------------------------------------
5| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
6--------------------------------------------------------------------------------
7| 0 | SELECT STATEMENT | | 20M| 146G| 102K (1)| 00:20:29 |
8| 1 | COUNT | | | | | |
9|* 2 | FILTER | | | | | |
10| 3 | INDEX FAST FULL SCAN| PK_ID | 20M| 146G| 102K (1)| 00:20:29 |
11--------------------------------------------------------------------------------
12Predicate Information (identified by operation id):
13---------------------------------------------------
14 2 - filter(ROWNUM=2)
15Note
16-----
17 - dynamic sampling used for this statement
18
19统计信息
20----------------------------------------------------------
21 0 recursive calls
22 0 db block gets
23 461958 consistent gets
24 221499 physical reads
25 0 redo size
26 1956 bytes sent via SQL*Net to client
27 374 bytes received via SQL*Net from client
28 1 SQL*Net roundtrips to/from client
29 0 sorts (memory)
30 0 sorts (disk)
31 0 rows processed</pre>
执行了4分钟,没有得到一条记录。尝试下面的方法。
方法2
明白了rownum的意思,意识到解决问题的办法,是再加一层查询,即里面括号的是我们要的数据,然后从上面选择rownum,其实就是行号为10到20的数据行。
1select *
2 from (select rownum no, Id,uniqueId,IP,IPNum,Mac,app_url,title,updatetime
3 from idouba.APP_CLUSTEREDAUDITLOG)
4 where no >= 10
5 and no < 20;
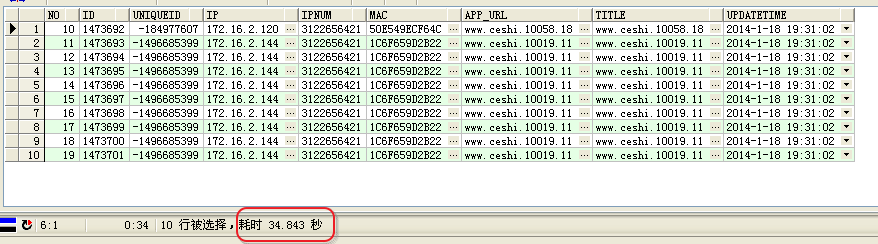
看到返回的是希望的10到19的记录,但是耗费的时间有点长,达到了34S。 查询计划如下
1已选择10行。
2已用时间: 00: 00: 35.43
3
4执行计划
5----------------------------------------------------------
6Plan hash value: 3666119494
7
8--------------------------------------------------------------------------------
9| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
10--------------------------------------------------------------------------------
11| 0 | SELECT STATEMENT | | 20M| 8965M| 102K (1)| 00:20:29 |
12|* 1 | VIEW | | 20M| 8965M| 102K (1)| 00:20:29 |
13| 2 | COUNT | | | | | |
14| 3 | INDEX FAST FULL SCAN| PK_ID | 20M| 8717M| 102K (1)| 00:20:29 |
15--------------------------------------------------------------------------------
16
17Predicate Information (identified by operation id):
18---------------------------------------------------
19 1 - filter("NO"<20 AND "NO">=10)
20Note
21-----
22 - dynamic sampling used for this statement
23
24统计信息
25----------------------------------------------------------
26 7 recursive calls
27 0 db block gets
28 462193 consistent gets
29 431581 physical reads
30 0 redo size
31 1174 bytes sent via SQL*Net to client
32 385 bytes received via SQL*Net from client
33 2 SQL*Net roundtrips to/from client
34 0 sorts (memory)
35 0 sorts (disk)
36 10 rows processed</pre>
方式3
尝试另外一种写法,看起来语义好像也差不多。先取出满足条件的前20条记录,然后在中间选择行号大于10的,即10到20行的记录。
1select *
2 from (select rownum no,Id, uniqueId,IP,IPNum,Mac,app_url,title,updatetime
3 from idouba.APP_CLUSTEREDAUDITLOG
4 where rownum < 20)
5 where no >= 10;

看到结果集,和2相同,但是耗费时间只有,时间是0.078S。问题出在哪儿呢,观察下查询计划。
1----------------------------------------------------------
2Plan hash value: 2707800419
3--------------------------------------------------------------------------------
4| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
5--------------------------------------------------------------------------------
6| 0 | SELECT STATEMENT | | 19 | 8911 | 3 (0)| 00:00:01 |
7|* 1 | VIEW | | 19 | 8911 | 3 (0)| 00:00:01 |
8|* 2 | COUNT STOPKEY | | | | | |
9| 3 | INDEX FAST FULL SCAN| PK_ID | 20M| 8717M| 3 (0)| 00:00:01 |
10--------------------------------------------------------------------------------
11
12
13Predicate Information (identified by operation id):
14---------------------------------------------------
15
16 1 - filter("NO">=10)
17 2 - filter(ROWNUM<20)
18
19Note
20-----
21 - dynamic sampling used for this statement
22
23统计信息
24----------------------------------------------------------
25 7 recursive calls
26 0 db block gets
27 264 consistent gets
28 0 physical reads
29 0 redo size
30 1174 bytes sent via SQL*Net to client
31 385 bytes received via SQL*Net from client
32 2 SQL*Net roundtrips to/from client
33 0 sorts (memory)
34 0 sorts (disk)
35 10 rows processed
对比2和3的查询计划。不用仔细分析,看计划步骤中间的每一步操作的涉及的行数,以及consistent?gets和physical?reads的不同量级即可理解的差不多。2是把获取所有数据,然后在上面选择10到20的行,3是只获取前20行,从中选择10行之后的数据行。
方式4
方式2中有order by,这是最常见的一种场景了,按照某个列排序,然后去中间某几条记录,其实就是某一页。
1select *
2 from (select rownum no, Id,uniqueId,IP,IPNum,Mac,app_url,title,updatetime
3 from (select * from idouba.APP_CLUSTEREDAUDITLOG order by Id))
4 where
5 no < 20 and
6 no >= 10
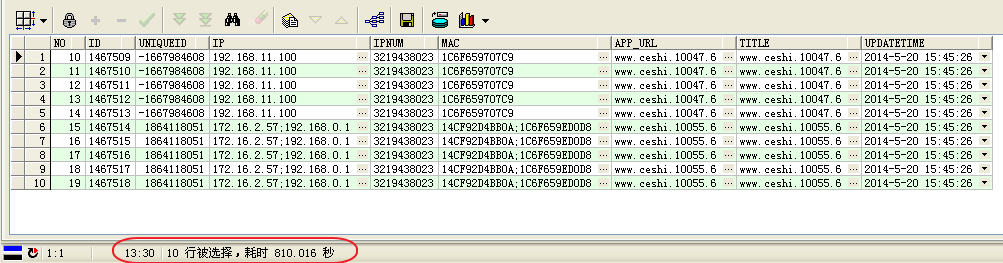
执行了13分钟,获取10行数据。看看查询计划。
1执行计划
2----------------------------------------------------------
3Plan hash value: 2624114486
4----------------------------------------------------------------------------
5| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
6----------------------------------------------------------------------------
7| 0 | SELECT STATEMENT | | 20M| 8965M| 463K (1)| 01:32:40 |
8|* 1 | VIEW | | 20M| 8965M| 463K (1)| 01:32:40 |
9| 2 | COUNT | | | | | |
10| 3 | VIEW | | 20M| 8717M| 463K (1)| 01:32:40 |
11| 4 | INDEX FULL SCAN| PK_ID | 20M| 146G| 462K (1)| 01:32:30 |
12----------------------------------------------------------------------------
13
14Predicate Information (identified by operation id):
15---------------------------------------------------
16
17 1 - filter("NO">=10 AND "NO"<20)
18
19Note
20-----
21 - dynamic sampling used for this statement
22
23统计信息
24----------------------------------------------------------
25 7 recursive calls
26 0 db block gets
27 460837 consistent gets
28 210018 physical reads
29 0 redo size
30 1196 bytes sent via SQL*Net to client
31 385 bytes received via SQL*Net from client
32 2 SQL*Net roundtrips to/from client
33 0 sorts (memory)
34 0 sorts (disk)
35 10 rows processed
方式5
方式3中加上order by条件。
1select *
2 from (select rownum no,
3 Id,
4 uniqueId,
5 IP,
6 IPNum,
7 Mac,
8 app_url,
9 title,
10 updatetime
11 from (select * from idouba.APP_CLUSTEREDAUDITLOG order by Id)
12 where rownum < 20)
13 where no >= 10;
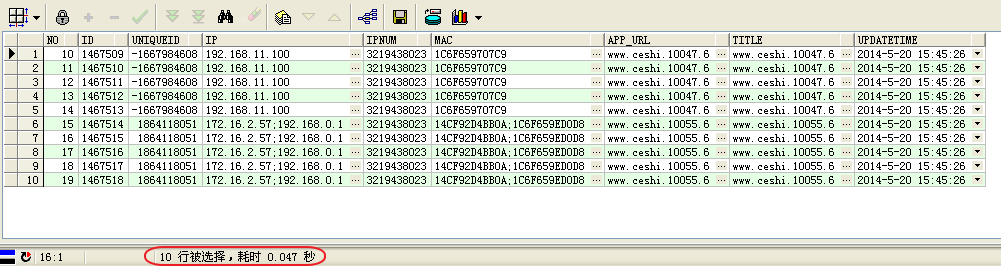
和方式2类似,花费时间也是毫秒级。 查询计划
1执行计划
2----------------------------------------------------------
3Plan hash value: 3021574494
4----------------------------------------------------------------------------
5| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
6----------------------------------------------------------------------------
7| 0 | SELECT STATEMENT | | 19 | 8911 | 3 (0)| 00:00:01 |
8|* 1 | VIEW | | 19 | 8911 | 3 (0)| 00:00:01 |
9|* 2 | COUNT STOPKEY | | | | | |
10| 3 | VIEW | | 20M| 8717M| 3 (0)| 00:00:01 |
11| 4 | INDEX FULL SCAN| PK_ID | 20M| 146G| 2 (0)| 00:00:01 |
12----------------------------------------------------------------------------
13Predicate Information (identified by operation id):
14---------------------------------------------------
15
16 1 - filter("NO">=10)
17 2 - filter(ROWNUM<20)
18
19Note
20-----
21
22 - dynamic sampling used for this statement
23
24统计信息
25----------------------------------------------------------
26 7 recursive calls
27 0 db block gets
28 240 consistent gets
29 2 physical reads
30 0 redo size
31 1196 bytes sent via SQL*Net to client
32 385 bytes received via SQL*Net from client
33 2 SQL*Net roundtrips to/from client
34 0 sorts (memory)
35 0 sorts (disk)
36 10 rows processed
方式6
使用minus
1select rownum no, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime from idouba.APP_CLUSTEREDAUDITLOG where rownum < 20
2minus
3select rownum no, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime from idouba.APP_CLUSTEREDAUDITLOG where rownum < 10
对应查询计划如下
1执行计划
2----------------------------------------------------------
3Plan hash value: 944274637
4-----------------------------------------------------------------------------------------
5| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
6-----------------------------------------------------------------------------------------
7| 0 | SELECT STATEMENT | | 19 | 12768 | | 5463K (51)| 18:12:46 |
8| 1 | MINUS | | | | | | |
9| 2 | SORT UNIQUE | | 19 | 8664 | 17G| 2731K (1)| 09:06:23 |
10|* 3 | COUNT STOPKEY | | | | | | |
11| 4 | INDEX FAST FULL SCAN| PK_ID | 20M| 8717M| | 102K (1)| 00:20:29 |
12| 5 | SORT UNIQUE | | 9 | 4104 | 17G| 2731K (1)| 09:06:23 |
13|* 6 | COUNT STOPKEY | | | | | | |
14| 7 | INDEX FAST FULL SCAN| PK_ID | 20M| 8717M| | 102K (1)| 00:20:29 |
15-----------------------------------------------------------------------------------------
16Predicate Information (identified by operation id):
17---------------------------------------------------
18
19 3 - filter(ROWNUM<20)
20 6 - filter(ROWNUM<10)
21
22Note
23-----
24
25 - dynamic sampling used for this statement
26
27统计信息
28----------------------------------------------------------
29 0 recursive calls
30 0 db block gets
31 58 consistent gets
32 0 physical reads
33 0 redo size
34 1174 bytes sent via SQL*Net to client
35 385 bytes received via SQL*Net from client
36 2 SQL*Net roundtrips to/from client
37 2 sorts (memory)
38 0 sorts (disk)
39 10 rows processed
方式7:
采用row_number()解析函数
1SELECT num, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime FROM(
2SELECT Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime,row_number() over(ORDER BY Id)AS num
3FROM idouba.APP_CLUSTEREDAUDITLOG t
4) WHERE num BETWEEN 10 AND 19;

执行计划如下:
1执行计划
2----------------------------------------------------------
3Plan hash value: 1698779179
4--------------------------------------------------------------------------------
5| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
6--------------------------------------------------------------------------------
7| 0 | SELECT STATEMENT | | 20M| 8965M| 463K (1)| 01:32:40 |
8|* 1 | VIEW | | 20M| 8965M| 463K (1)| 01:32:40 |
9|* 2 | WINDOW NOSORT STOPKEY| | 20M| 8717M| 463K (1)| 01:32:40 |
10| 3 | INDEX FULL SCAN | PK_ID | 20M| 8717M| 462K (1)| 01:32:30 |
11--------------------------------------------------------------------------------
12Predicate Information (identified by operation id):
13---------------------------------------------------
14
15 1 - filter("NUM">=10 AND "NUM"<=19)
16 2 - filter(ROW_NUMBER() OVER ( ORDER BY "ID")<=19)
17
18Note
19-----
20
21 - dynamic sampling used for this statement
22
23统计信息
24----------------------------------------------------------
254 recursive calls
26 0 db block gets
27 123 consistent gets
28 0 physical reads
29 0 redo size
30 1197 bytes sent via SQL*Net to client
31 385 bytes received via SQL*Net from client
32 2 SQL*Net roundtrips to/from client
33 0 sorts (memory)
34 0 sorts (disk)
35 10 rows processed
1 - filter("NUM">=10 AND "NUM"<=19) 2 - filter(ROW_NUMBER() OVER ( ORDER BY "ID")<=19)
Note
- dynamic sampling used for this statement
统计信息
三、总结
为了简单期间,只是从2千万条记录中查询10到20行的数据。考察发现如下三种方式性能上是可以接受的3、5、6、7写法是可以接受的(3和5其实差不多,如果如实验所示,在order?by列上是索引聚集的话),都是毫秒级可以出结果。 但是当查询后若干条记录的时候,如一千万行的前十行记录。每种也都需要几分钟的执行时间。
- 使用row_number函数
1SELECT num, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime FROM(
2SELECT t.*,row_number() over(ORDER BY Id )AS num
3FROM idouba.APP_CLUSTEREDAUDITLOG t
4)
5WHERE num BETWEEN 9999990 AND 10000000;
-
三层的select
1select * 2 from (select rownum no, 3 Id, 4 uniqueId, 5 IP, 6 IPNum, 7 Mac, 8 app_url, 9 title, 10 updatetime 11 from (select * from idouba.APP_CLUSTEREDAUDITLOG order by Id) 12 where rownum < 10000000) 13 where no >= 9999990; -
使用minus关键字
1select rownum no, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime from (select * from idouba.APP_CLUSTEREDAUDITLOG order by Id) where rownum < 10000000 2minus 3select rownum no, Id, uniqueId, IP, IPNum, Mac, app_url, title, updatetime from (select * from idouba.APP_CLUSTEREDAUDITLOG order by Id) where rownum < 9999990
性能比较如下:
| 使用row_number函数 | 三层的select | 使用minus关键字 | |
|---|---|---|---|
| 第1000万行前面10行 | 766.234 | 404.125 | 795.562 |
| 第100万行前面10行 | 12.468 | 12.438 | 26.125 |
| 第10万行前面10行 | 1.265 | 1.125 | 1.5 |
| 第1万行前面10行 | 0.329 | 0.312 | 0.25 |
| 第1000行前面10行 | 0.438 | 0.468 | 0.203 |
| 第100行前面10行 | 0.25s | 0.219s | 0.265 |
五、最后
本来到这里几种对照就应该结束了。尤其是场景2和场景4,场景3和场景5只是多了个order by子句,因为本来就是以ID列为主键的索引组织表。理解就是按照ID顺序来存记录的,则是否显示的写order by子句应该没有影响,却观察到2、3的结果和4、5的结果不一样呢/sp为了主题集中期间,这个问题放在下一篇介绍。
附:
1CREATE TABLE "idouba"."APP_CLUSTEREDAUDITLOG"
2 ( "ID" NUMBER NOT NULL ENABLE,
3 "UNIQUEID" NUMBER,
4 "POLICYID" NUMBER,
5 "IP" VARCHAR2(200) NOT NULL ENABLE,
6 "IPNUM" NUMBER NOT NULL ENABLE,
7 "MAC" VARCHAR2(200),
8 "USERVISIT" VARCHAR2(100),
9 "PHONE" VARCHAR2(200),
10 "GROUPNAME" VARCHAR2(100),
11 "PORT" NUMBER,
12 "PKI" VARCHAR2(200),
13 "PKIUSERID" VARCHAR2(200),
14 "APP_URL" VARCHAR2(200),
15 "TITLE" VARCHAR2(200),
16 "REQUESTS" VARCHAR2(1000),
17 "REQIDENTITYCARD" VARCHAR2(1000),
18 "REQCARCARD" VARCHAR2(1000),
19 "REQPHONEKEY" VARCHAR2(1000),
20 "ANSIDENTITYCARD" VARCHAR2(3000),
21 "ANSCARCARD" VARCHAR2(3000),
22 "ANSPHONEKEY" VARCHAR2(3000),
23 "UPDATETIME" DATE,
24 "PIGEONHOLE" VARCHAR2(200),
25 "AUDITTYPE" NUMBER,
26 "TITLEID" NUMBER NOT NULL ENABLE,
27 "SUBTITLEID" NUMBER,
28 "IFWARN" NUMBER,
29 "SERVERIP" VARCHAR2(200),
30 "DOMAINNAME" VARCHAR2(200),
31 "PKIUSERNAME" VARCHAR2(200),
32 CONSTRAINT "PK_ID" PRIMARY KEY ("ID") ENABLE
33 ) ORGANIZATION INDEX NOCOMPRESS PCTFREE 10 INITRANS 2 MAXTRANS 255 LOGGING
34 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
35 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
36 TABLESPACE "USERS"
37 PCTTHRESHOLD 50 OVERFLOW
38 PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 LOGGING
39 STORAGE(INITIAL 16384 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
40 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
41 TABLESPACE "USERS" ;
42 CREATE UNIQUE INDEX "idouba"."PK_ID" ON "idouba"."APP_CLUSTEREDAUDITLOG" ("ID")
43 PCTFREE 10 INITRANS 2 MAXTRANS 255
44 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
45 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
46 TABLESPACE "USERS" ;
47
48 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" ADD CONSTRAINT "PK_ID" PRIMARY KEY ("ID")
49 USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255
50 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
51 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
52 TABLESPACE "USERS" ENABLE;
53
54 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" MODIFY ("ID" NOT NULL ENABLE);
55 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" MODIFY ("IP" NOT NULL ENABLE);
56 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" MODIFY ("IPNUM" NOT NULL ENABLE);
57 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" MODIFY ("TITLEID" NOT NULL ENABLE);
58 ALTER TABLE "idouba"."APP_CLUSTEREDAUDITLOG" ADD CONSTRAINT "PK_ID" PRIMARY KEY ("ID")