KubeCon2021:服务网格替代 Hystrix 提升在线视频服务韧性的生产实践
记录在KubeCon2021上发表的技术演讲《Online Video upgrades resilience from SC Circuit Breaker to Service Mesh》,和世宇做的一个技术实践分享,总结了下一起把网格在人人视频中落地的部分经验。。
议题:
作为中国领先的在线视频共享平台,人人视频业务的快速发展给其 IT 基础设施带来了巨大挑战。日益增长的复杂性、容量和韧性要求给当前基于 Spring Cloud 熔断器的微服务带来了新的问题。
在KubeCon2021上,华为云应用服务网格架构师张超盟和人人视频技术主管徐世宇介绍了大规模生产环境中的服务网格韧性实践,包括不健康实例的透明自动隔离、故障自动恢复和自我修复、连接池管理、重试、限流、超时和分布式跟踪等。通过分析熔断器模式和比较 Spring Cloud 熔断器与服务网格在各自生产实践中不同的实现方式,结果表明优化不只是改善了系统的可靠性和可用性,还使得开发和操作工作更简单便捷。
As one leading Online Video sharing platform in China, RR's rapid business development introduce great challenge on its IT infrastructure. The increasing complexity, capacity and resilience requirement brings new problems to current Spring Cloud circuit breaker based micro services.
In this presentation, Chaomeng and Shiyu will focus on service mesh resilience practice in large scale production environment, including transparent auto-isolation of the unhealthy instance, auto-recovery and self-healing, connection pool management, retry, fine gained rate limit and distributed tracing, latency metrics. By analyzing circuit breaker pattern and comparing the different implementation of Spring Cloud circuit breaker and service mesh in their production practice, they show that the optimization not only improves system reliability and availability but also makes dev and ops works simpler and easier.
正文:

我是张超盟,来自华为云。本次大会我和人人视频的架构师徐世宇带来关于服务韧性的分享。结合一个生产中的实际案例,介绍网格等云原生解决方案替换原有基于Spring Cloud Hystrix在提升服务韧性的实践细节。

演讲主要包含三部分的内容:
- 首先,概要的介绍韧性的背景;
- 第二部分,案例的业务背景和架构,包括原有Spring Cloud框架中基于Hystrix的韧性能力的使用细节;
- 第三部分是本次演讲的重点内容,介绍服务网格等云原生技术全面提升服务韧性的实践。

关于韧性

“任何事物任何时候都可能故障”,这是AWS的沃纳关于故障的经典描述。在系统架构设计,特别是韧性、可靠性可用性设计中被广泛引用。因为不断的经验教训告诉我们,对于一个系统,我们所面临的不是是否失败,而是什么时候失败的问题。
不管前期我们投入多少财力、精力和资源去加固系统,失败总不可避免。预防失败是一方面,更重要的是接受失败,在失败时候保证业务影响小,并尽快的从失败中恢复。
韧性正是描述了这样一种能力,韧性强调的是系统在过载、故障或在遭受攻击的时候还能够使用。韧性告诉我们,虽然我们并不想要失败,但是我们承认失败会发生的现实。因而我们需要为失败而设计系统,在故障发生时,减少故障对系统的影响,进而减小对用户业务的影响,特别是核心业务的影响。即构建能处理这些故障并自我修复的系统。有个著名的说法,韧性不能保证你多挣到钱,但是可以保证你少赔钱。套用当前一个流行的说法是,产品的竞争力或者业务能力能帮我们冲击更高的上线,但是韧性能帮助我们守住我们的下线。
韧性应用于工程世界的所有系统。计算机世界里韧性设计一直是一个非常重要的研究方向。不管是自研的传统服务,还是现网上运行的云服务。
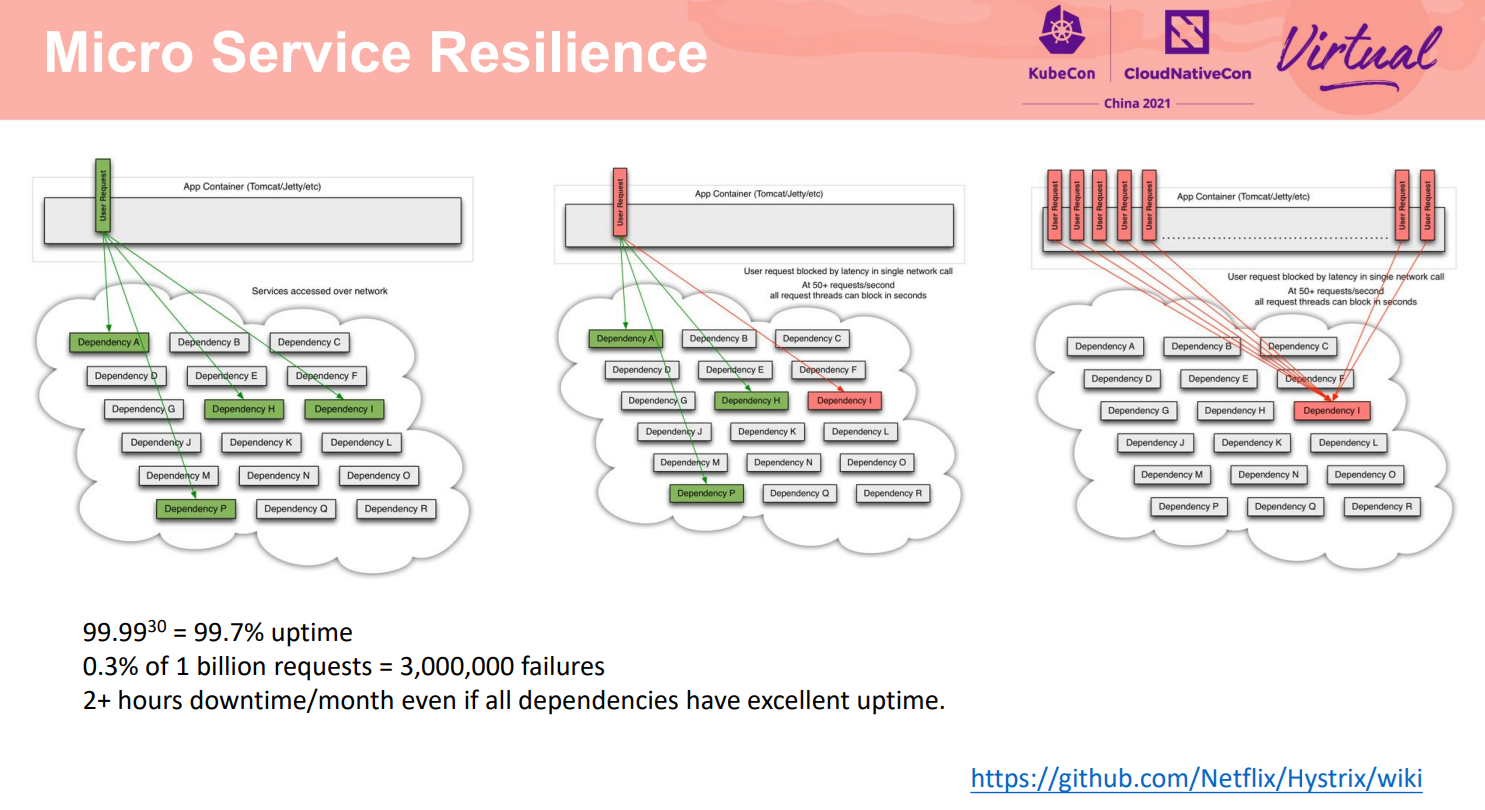
在本次分享中我们将聚焦服务间访问的韧性,主要是客户场景中微服务的服务间访问比较频繁的场景。
以上关于故障的观点在规模小的系统里体现可能不明显,在规模比较大的系统里尤其是微服务场景下体现的非常明显。局部的访问影响整个系统,进而影响最终业务。
如Hystrix关于韧性的理论模型中描述了:对于依赖 30 个服务的应用程序,即使每个服务的正常运行时间为 99.99%,系统总的正常运行也只有99.7%,每个月会引入超过2个小时的停机。考虑到微服务分布式系统的网络带宽、延时、可靠性、安全、业务自身问题、资源等情况会变的更加复杂。
业务场景和挑战
接下来由人人视频的架构师徐世宇介绍实践的实际场景、系统架构,和早期基于Spring Cloud的熔断器Hystrix提供微服务韧性保护的实践细节以及遇到的挑战。

人人视频是以美日韩泰视频内容为主的在线视频点播APP。当前拥有2亿+注册用户,日活最高达到1000万,月活用户5500万,并且近日人人视频迎来了第七个周年纪念日。作为中国领先的在线视频共享平台,人人视频业务的快速发展给其 IT 基础设施带来了巨大挑战。
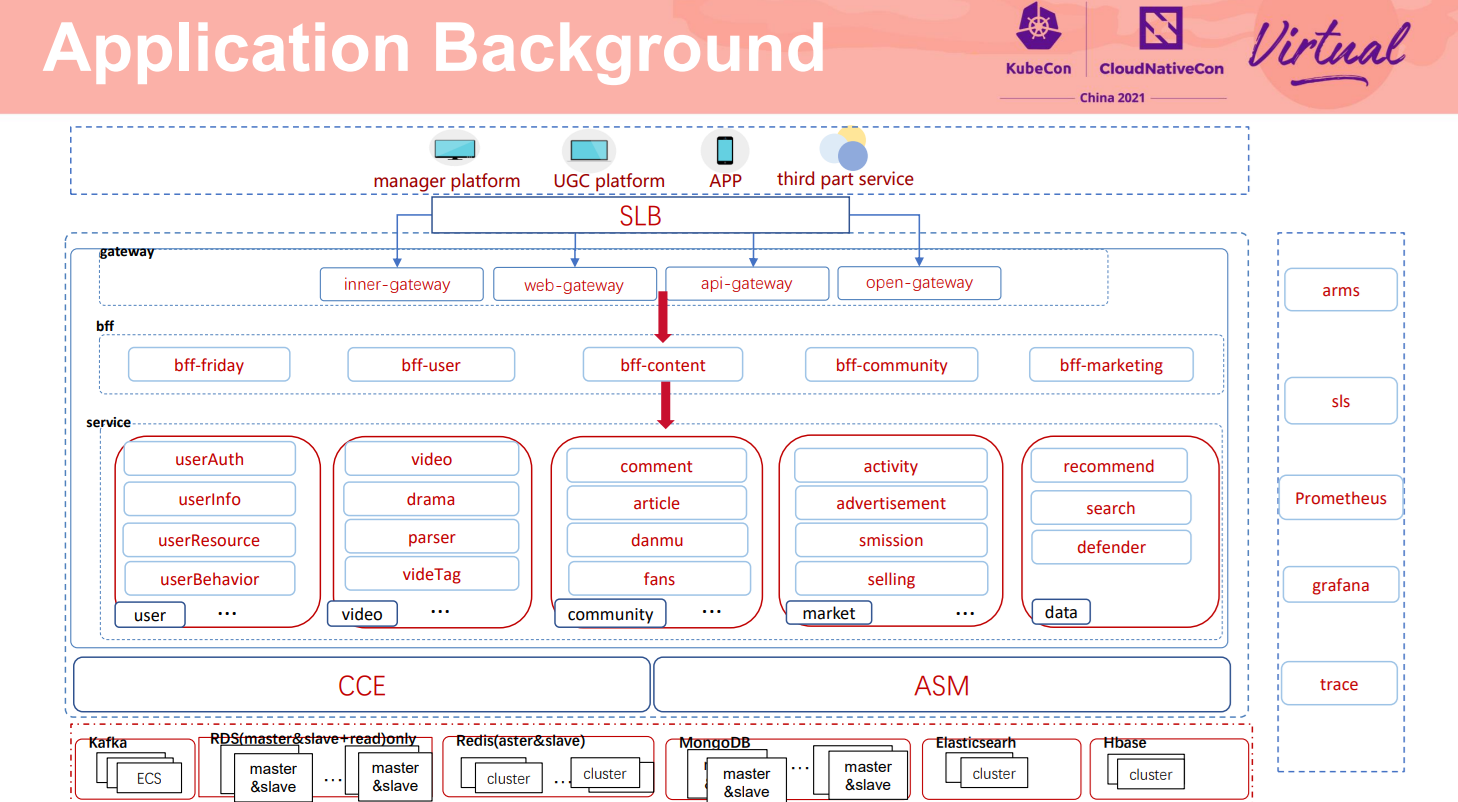
人人视频主要业务架构如上图所示,该业务架构主要分为四层:网关层、业务聚合BFF层、基础服务层、中间件层。其中基础服务层由用户中心、内容中心、市场变现中心、数据中心五大中心构成:
- 用户中心主要以用户信息、用户标签鉴权构成;
- 内容中心主要以视频基础信息、视频解析、视频分发、视频标签等媒资处理构成;
- 社区中心主要包含评论、弹幕交互、社区广场;
- 市场变现中心主要包含活动、任务、广告、商城、支付等内容;
- 数据中心以智能推荐、海量数据搜索、业务风控等构成;
中间件层主要包含kafka、redis等高并发场景组件,并且采用了mysql、mongoDB、Elasticsearch、Hbase等多元化数据存储方案。整个业务容器由CCE进行托管编排,并且采用了ASM进行服务的韧性保护。
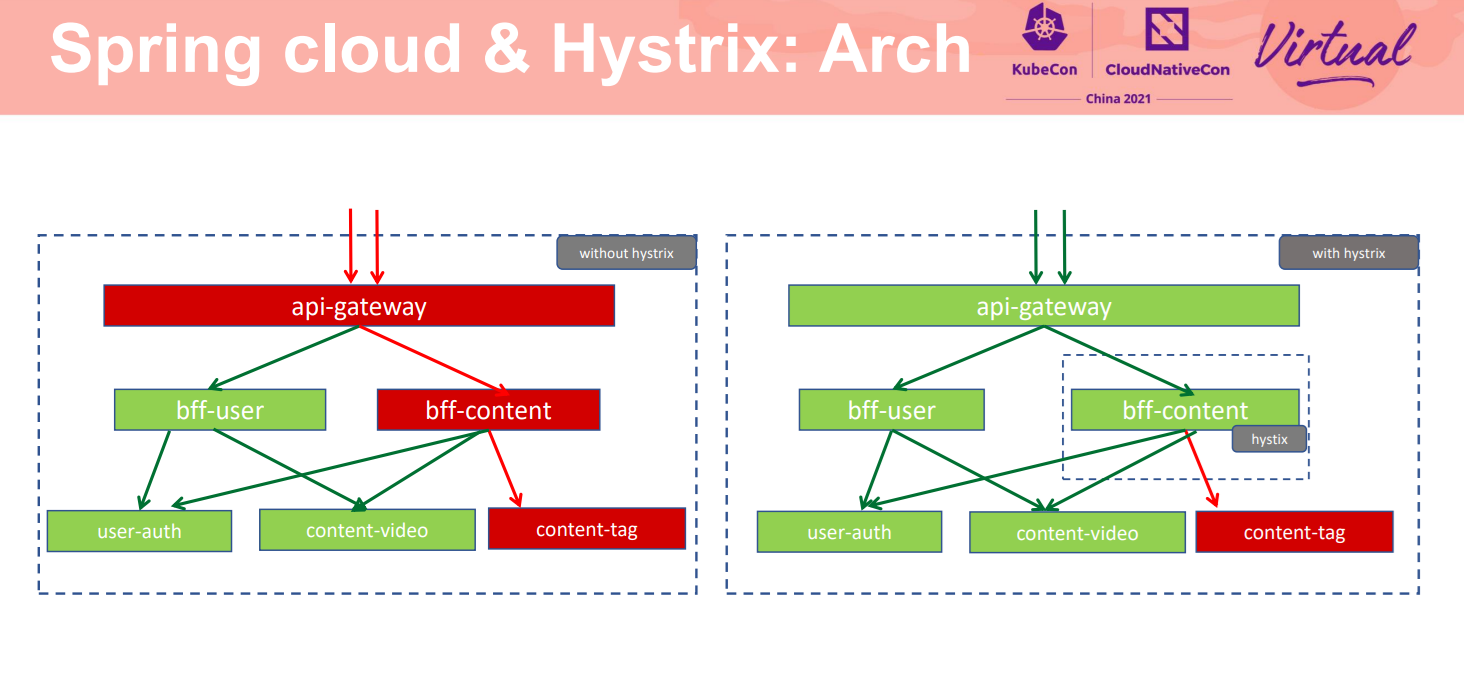
随着人人视频业务蓬勃发展,其架构模式也进行了多次迭代调整。早期由于业务量级不够大,架构上也缺乏相应的容错机制保护,比如未采用熔断机制进行微服务治理。此架构模式下,当下游服务出现故障时会积压阻塞上游服务的请求,从而使得上游服务进行级联性的崩溃,最终导致服务集群的雪崩而完全不可用。
为解决此致命性问题,我们在架构中引入了hystrix熔断保护机制。此保护模式下,当下游服务出现故障时,上游服务能快速的对下游服务采用熔断降级的措施,从而使得该服务不会受到下游异常服务的影响。
下面主要介绍hystrix配置在人人视频的实践,例如在updateUser场景主要设置coreSize为20,maximumSize为40,maxQueueSize为1000,queueSizeRejectionThreshold为800;此设置和基本的线程池原理一致,当业务请求创建的线程数还未达到coreSize时会新建线程去处理,当创建的线程数达到coreSize之后的业务请求会放入队列等待处理,当队列里等待的业务数达到maxQueueSize时会再新建线程处理,直到达到maximumSize。这是hystrix的一个线程池设置,此时我们又该如何设置熔断触发的参数。熔断触发主要由断路器参数进行控制,比如我们在默认的时间窗10s内至少有200个请求(requestVolumeThreshold:200)并且错误率达到了50%(errorThresholdPercentage:50)即触发熔断,触发熔断10000ms(sleepWindowInMilliseconds:10000)后会释放少量请求去探测下游服务是否正常,如果正常则断路器关闭,后面的所有请求则正常请求下游服务,如果不正常断路器则继续打开直到下一个休眠时间后继续探测下游服务正常与否。

但随着业务架构的不断迭代调整,使用hystrix进行熔断保护的弊端也随之产生。当前人人视频正在利用go语言的优势将BFF层服务采用go进行重构,但由于hystrix组件的语言限制,并不能在go的框架中进行使用,并且hystrix的使用代码侵入性强,比如需要引入相应的jar包,使用相关的注解,开启相关的配置等。并且当我们需要使用限流方案时,hystrix也不能直接提供成熟的解决方案。当我们使用混沌工程来进行正常业务的故障注入以便更早的暴露出问题时,hystrix也将无能为力。针对这些问题,我们也在探索一些新的方案来解决,实践证明网格等云原生技术能很好地解决业务中碰到的这些问题。
服务网格韧性实践
下面我们介绍服务网格的云原生解决方案中,如何提供完整的韧性能力,在实践中帮助用户商业成功。
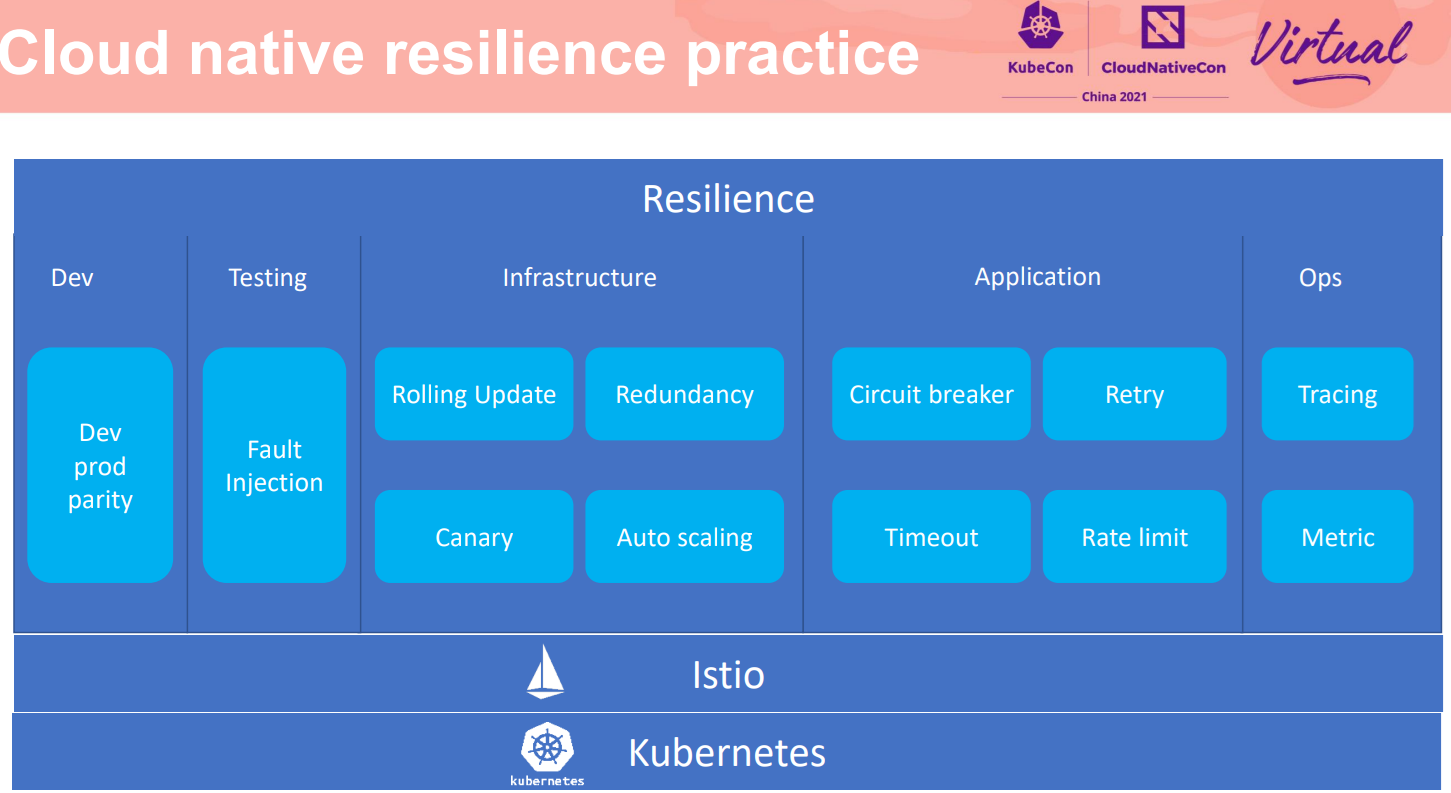
在基于云原生的韧性方案中,我们不只提供了面向应用的熔断器,而是提供了从开发、测试到基础设施,到应用运行的整个韧性保证。也包括运行期的Ops,保证快速发现问题,进而解决问题。从而做到故障模拟与测试、隔离与恢复、定界与定位等全纬度的处理。进而避免故障蔓延与故障影响业务,特别是对核心业务的影响。
熔断 Circuit Breaker
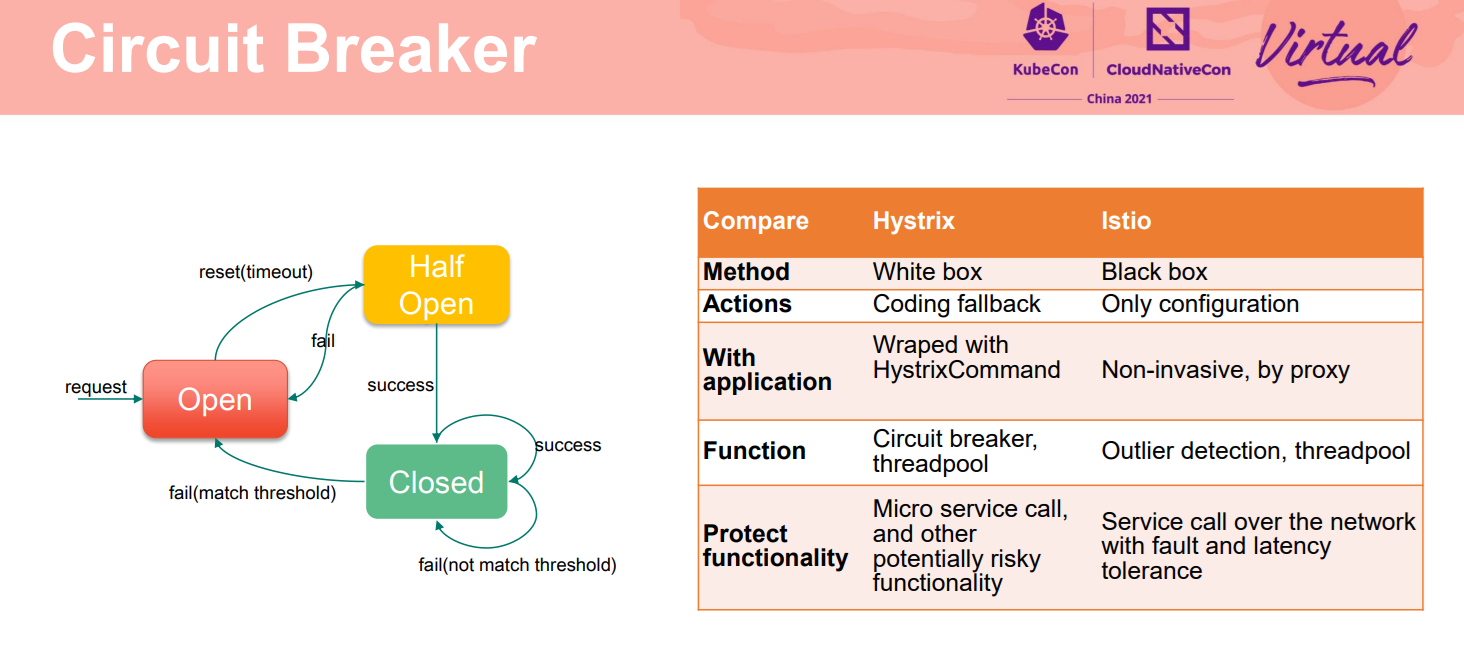
左图是项目中之前实施的经典的Hystrix的状态迁移图。一段时间内实例连续的错误次数超过阈值则进入熔断开启状态,不接受请求;隔离一段时间后,会从熔断状态迁移到半熔断状态,如果正常则进入熔断关闭状态,可以接收请求;如果不正常则仍然进入熔断开启状态。
网格中虽然没有显式提供这样一个状态图,但是Istio中异常点检查的阈值规则也都是这样设计的。两者的不同是Spring Cloud的熔断是在SDK中Hystrix执行,Istio中是数据面proxy执行。Hystrix因为在业务代码中,允许用户通过编程做一些控制。
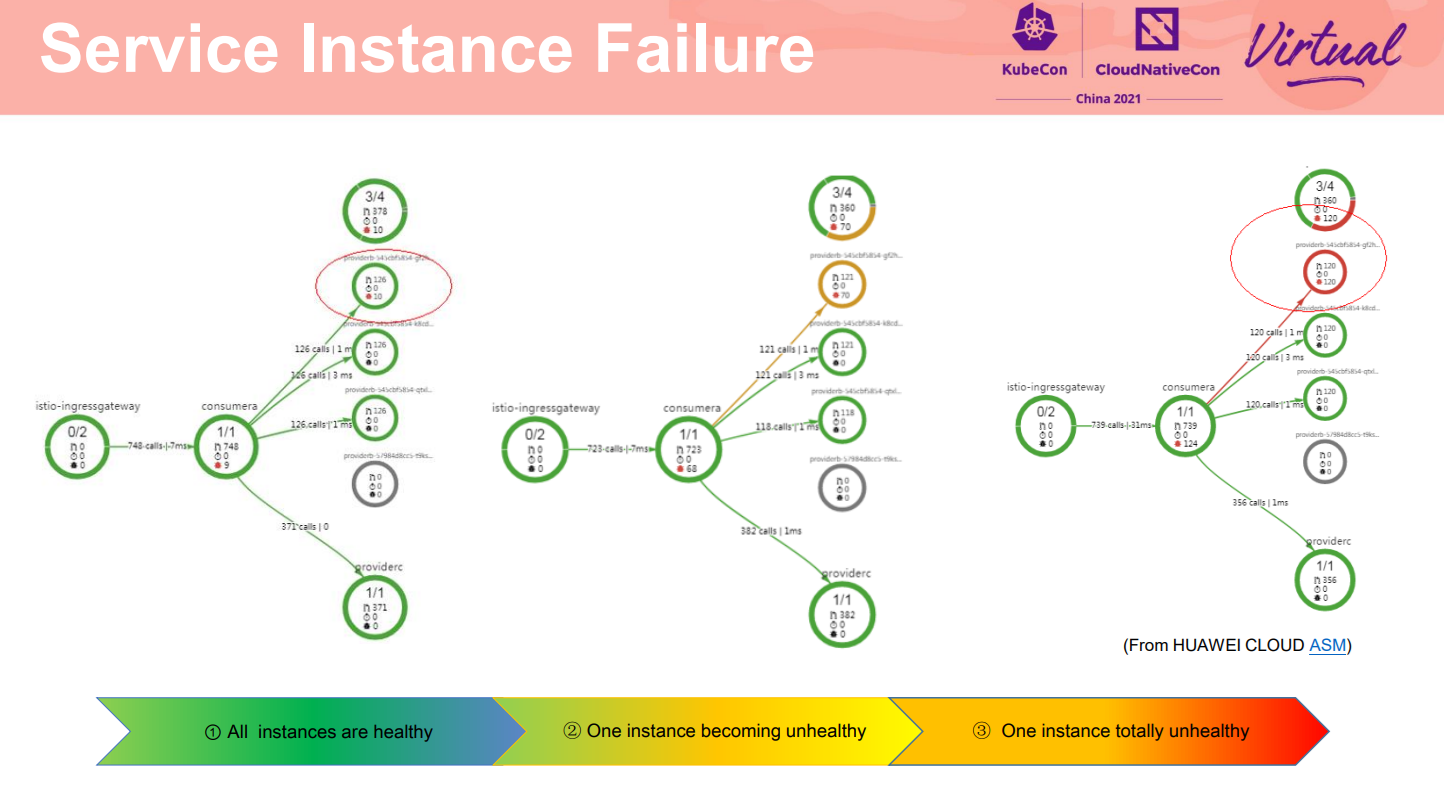
下面看下网格的熔断实施的效果。这是一个典型的故障场景。其中一个服务实例故障,当没有进行任何故障处理措施时,流量还是均衡的分发到三个实例上,对于服务访问者而言,将会有三分之一的几率得到失败的应答,影响最终用户的业务。

**韧性的重要一点要求是故障发生时不影响用户最终业务。**对于这种部分实例故障,基于网格的异常点检查,隔离故障实例使得请求只发到健康的实例上。具体规则是:考察服务实例的访问情况,在一段时间内如果连续失败次数达到阈值条件,则该实例会被隔离,得不到流量。
如图配置:当一个实例在4分钟内,连续5次502 503 或504故障,将会被隔离10分钟;在这10分钟里,隔离的实例会被标记为不健康,不能得到流量。在10分钟后,这个实例会被自动加回来,尝试重新接收流量。如果继续检测出是故障,则隔离时间会加倍。如这个例子中,第二次连续故障会被隔离20分钟,下次30分钟,从而使得一直故障的实例一直被隔离,减少对业务的影响。
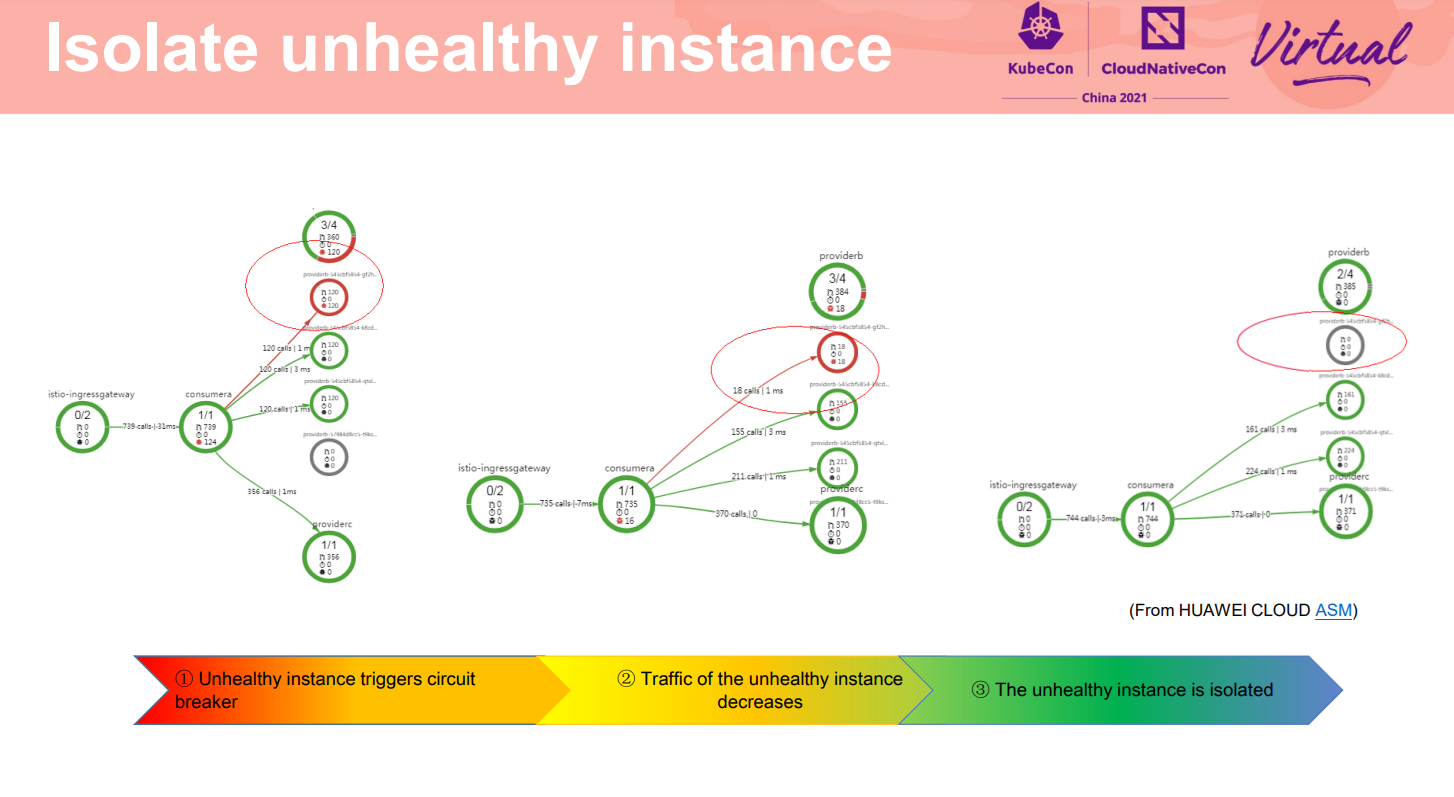
**隔离故障的详细过程如下:**从拓扑图上可以看到第一个实例异常满足熔断阈值,触发了熔断,网格数据面向这个故障实例上分发的流量逐渐减少,直到完全没有流量,即故障实例被隔离。
这样,所有访问流量只会分发到两个健康实例上,通过这种熔断保护保障服务整体访问的成功率。
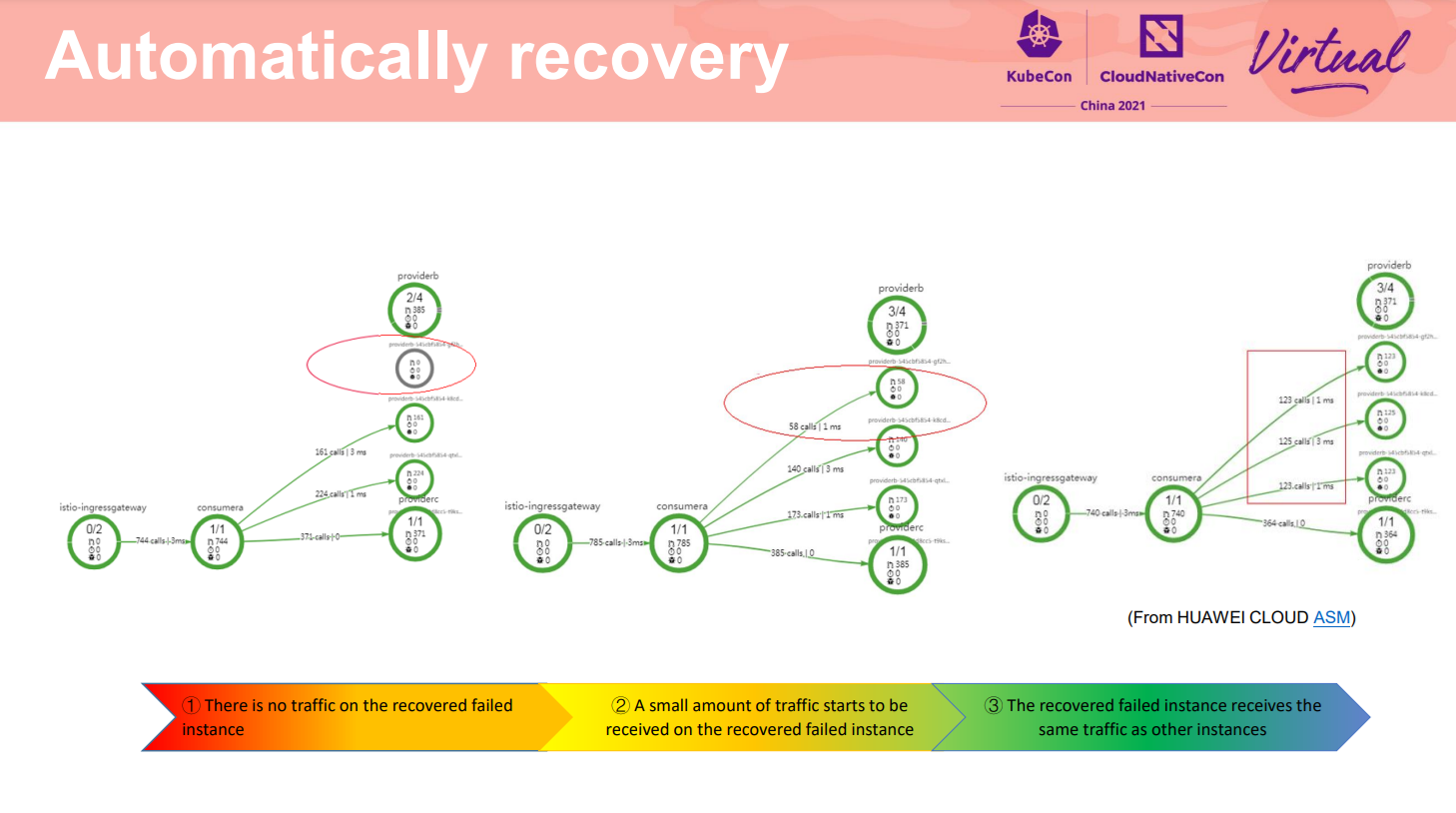
**除了隔离外,韧性中另外有一个非常重要的要求是系统的故障自愈能力。这里三个流量拓扑演示了从刚才的故障中恢复的过程。**可以看到:初始状态这个故障实例被隔离中,没有流量;当实例自身正常后,网格数据面在将其隔离配置的间隔后,重新尝试分配流量,当满足阈值要求则该实例会被认为是正常实例,可以和其他两个实例一样接收请求。最终可以看到三个实例上均衡的处理请求。即实现了故障恢复。

网格熔断提供的另外一组保护机制是非侵入的连接池管理。可以对四层的连接,七层的请求进行限制。当实际的连接和请求超过配置的阈值时,则断路连接,从而保护上游的服务。
如配置对目标服务,最大允许80个连接,这里应用于一般TCP或HTTP1,因为HTTP2对于一个上游实例使用一个连接。最大请求数为800,用来控制HTTP2的请求数。对于HTTP1,通过最大连接数即可以控制。等待连接上发送的最大请求数为1000,应用于HTTP1,因为HTTP2请求可以直接发送。另外,每个连接上最多10个请求。
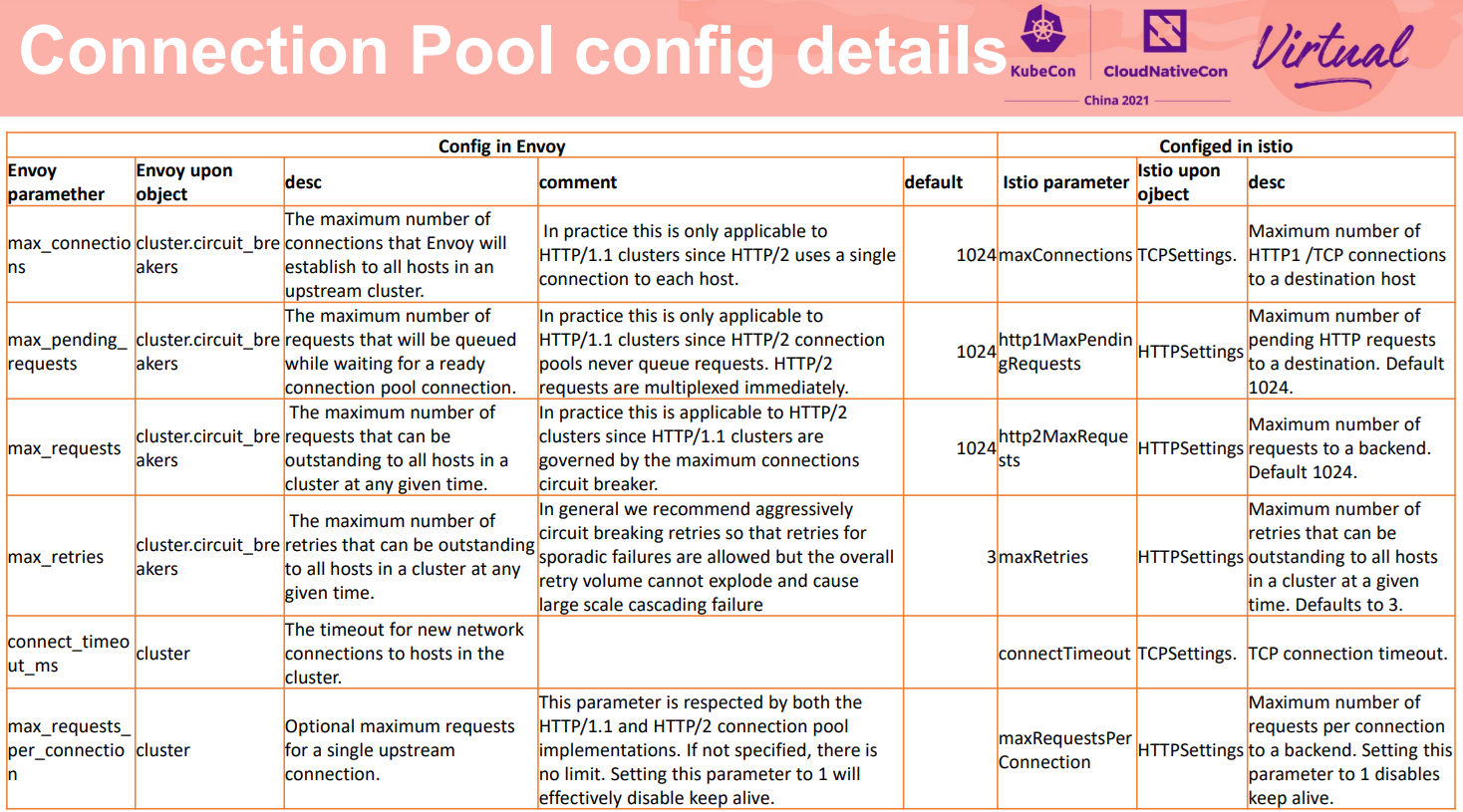
这里附了个参照,Istio控制面对于上面的参数的配置和分类和Envoy稍有不同,在实际使用中,有使用者经常搞混。可以看到Istio按照协议分为TCP和HTTP的配置。而Envoy中有些参数是配置上游服务的,有些参数是配置在熔断器上。
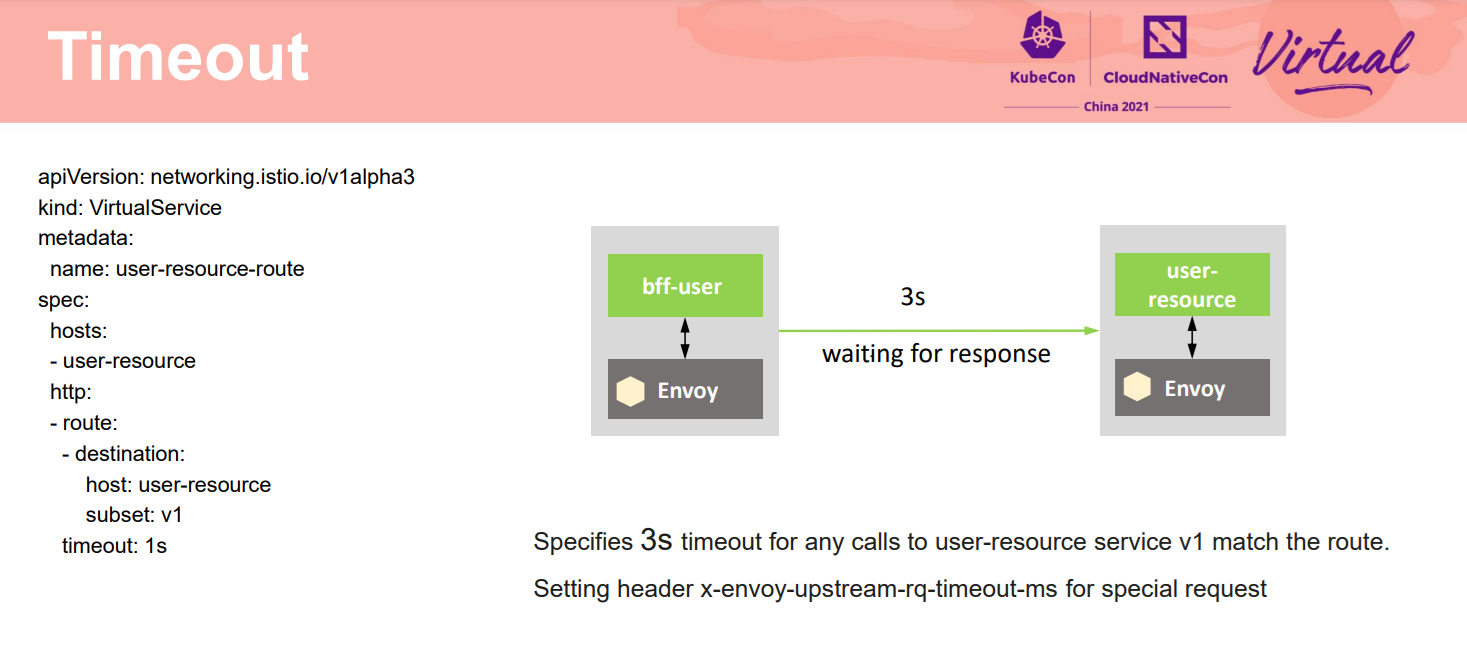
Timeout也是韧性的一个重要手段。设置服务超时来避免服务一直卡在某个请求上,影响业务也影响对资源的一直占用。如在bff服务访问后端业务服务时,配置了一个3s的超时。客户端的 proxy在代理bff发起请求时,会考察超时时间,超过这个时间,则会取消操作。在实际使用中,超时时间的配置需要结合业务。避免过长,导致一直等待一个不会返回应答的请求,也避免过短,导致合理的较慢请求还没返回就超时取消。
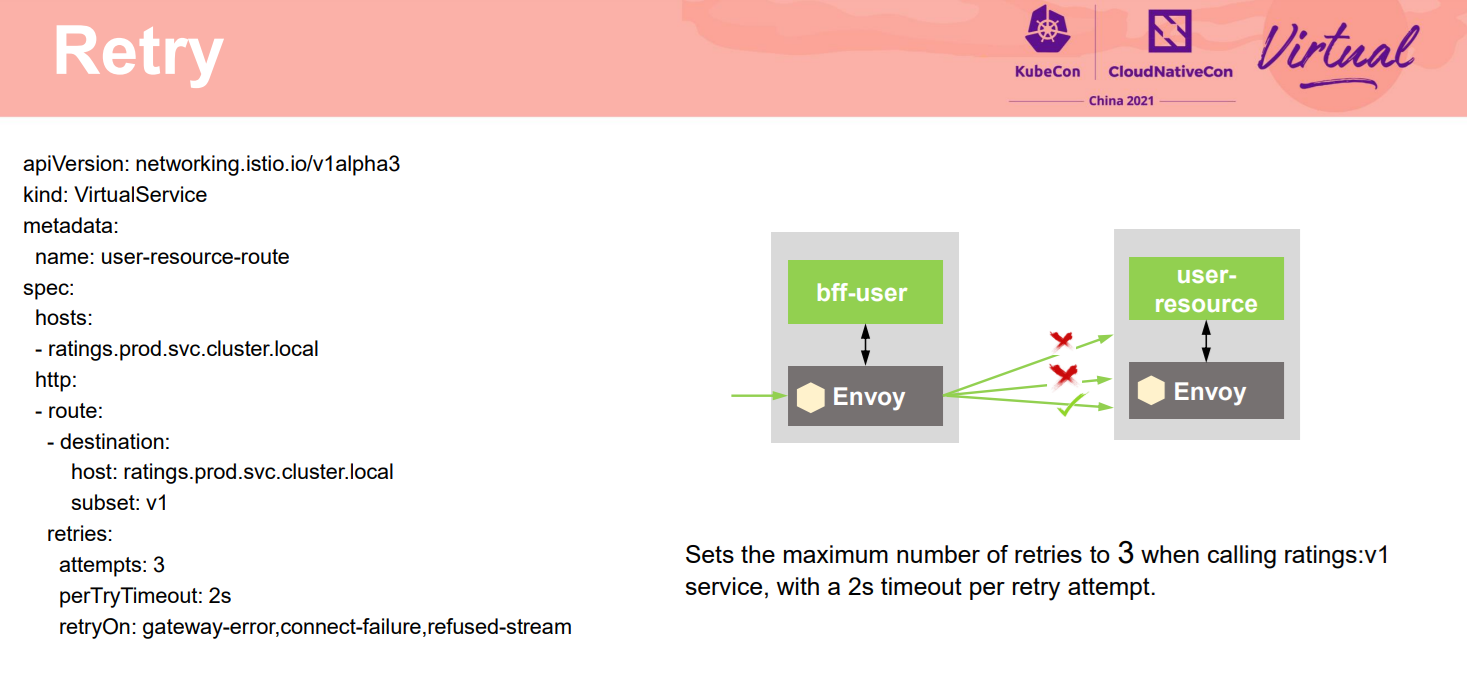
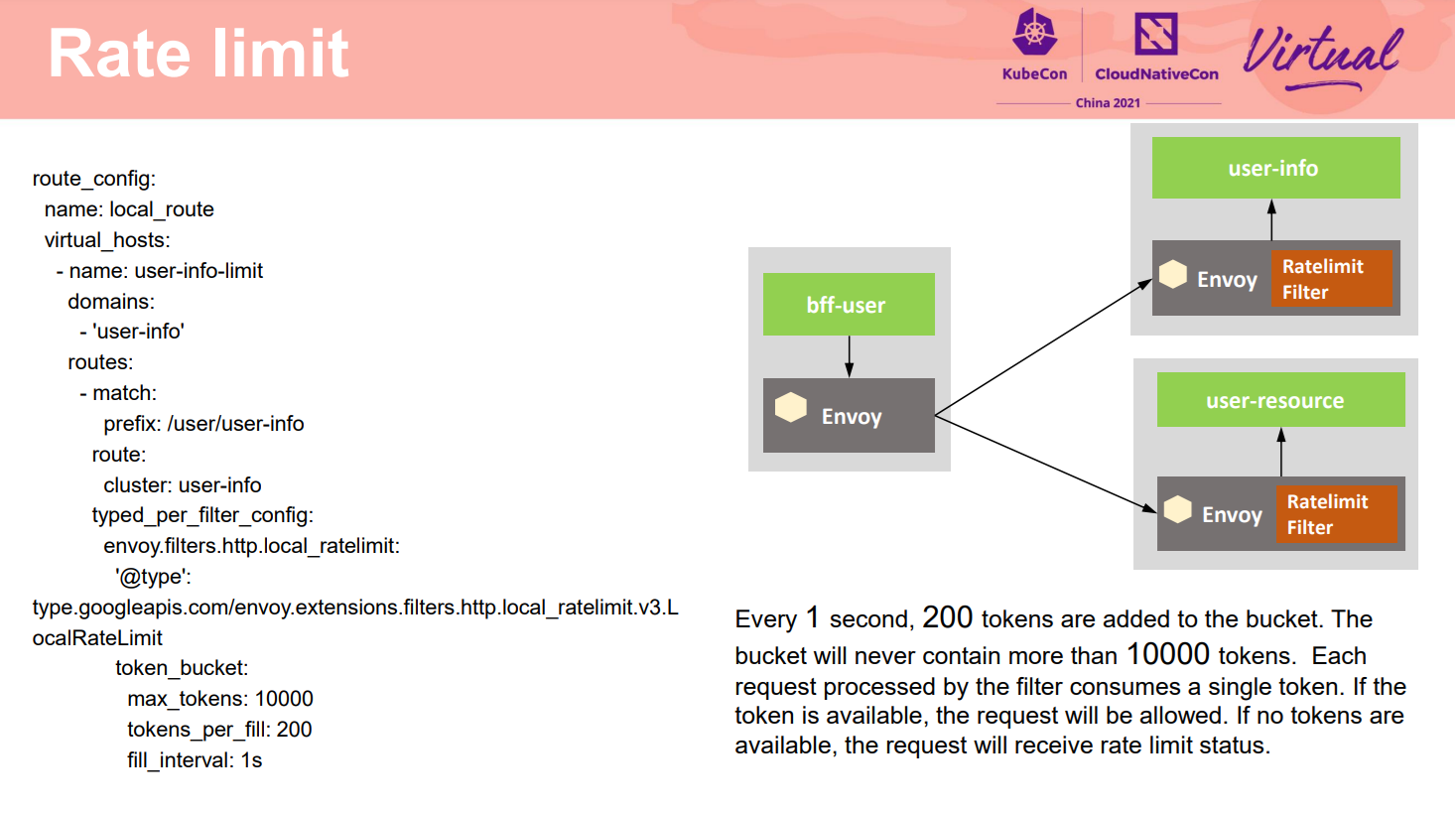
熔断虽然有各种优点,但因为执行位置在服务调用方,可能会被绕过或者没有使用能力的客户端不生效。限流可以作为另外一种手段来进行保护。限流是保障服务高可用运行的重要手段,特别是对于一些关键的服务,经常需要综合多种因素进行容量规划。当出现瞬时的流量高峰时,通过限流的阈值时则会拒绝服务,从而防止系统过载,进而保障应用的可用性。一般结合业务特点通过一些配置可以做到在负载比较高时先保护核心业务的服务。保证过载的时候能提供基本能力,从而提高系统韧性。网格可以对网格内部任意一个微服务进行非侵入、透明的限流,可以限制四层的连接数,也可以限制七层的请求数。
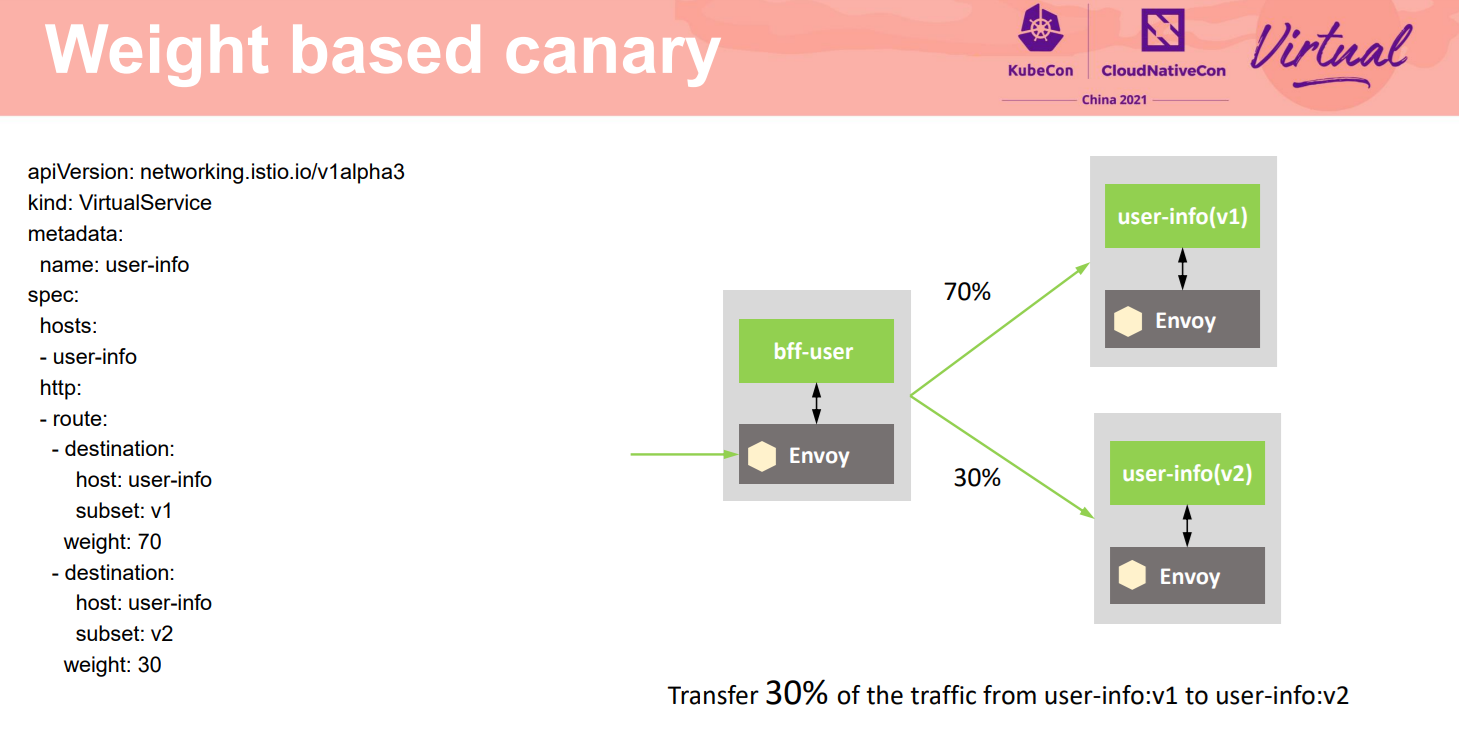
提高系统韧性的另外一个重要方面是尽量降低变更引起的风险。灰度是在发布过程中保证业务平稳运行升级的重要手段,在灰度过程中,新老版本同时生成环境在线,新版本只切分少量流量出来,在确认新版本没有问题后,再逐步加大流量比例。当新版本识别到有问题时,只会影响少量流量,并可以快速回退。
灰度发布的核心部分是配置灰度的流量规则。网格的非侵入流量切分能力,能够灵活配置规则给不同版本分配流量。如这个例子中从生产版本V1中切分30%的流量到V2版本,验证V2版本的运行情况,确定是否在V2稳定运行后,把所有流量都切换到灰度的V2版本上。
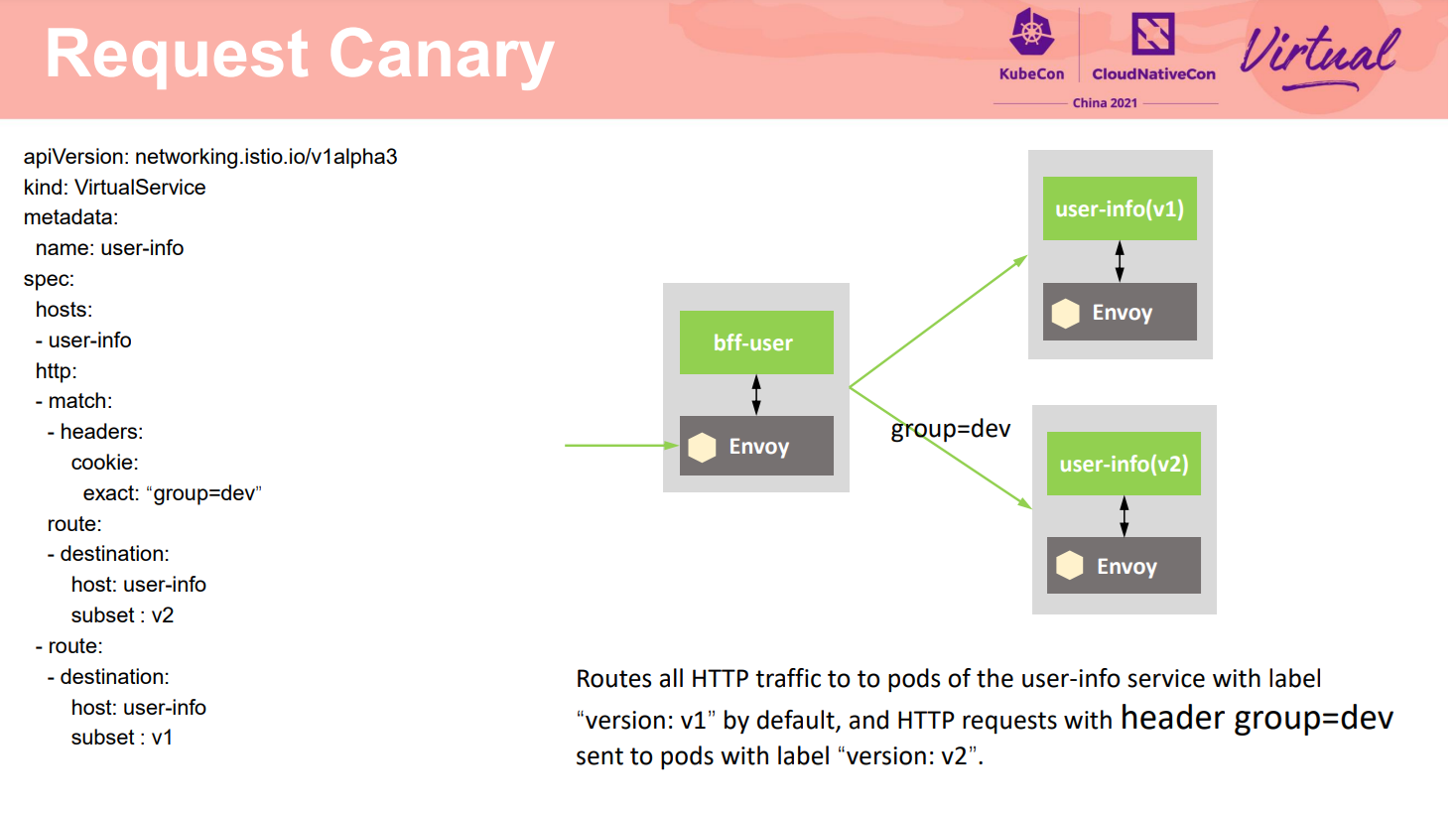
除了支持基于前面流量比例的灰度策略外,网格还支持非常灵活的基于请求内容的灰度策略。请求中的任何字段都可以作为流量标准,从而精准的将只是某种特点的流量分发到灰度版本,其他特征的流量仍然路由到原有版本上,对大部分用户不会产生影响。如实例中只有请求的Header group取值dev的流量分发到灰度V2版本,其他流量还走V1版本。
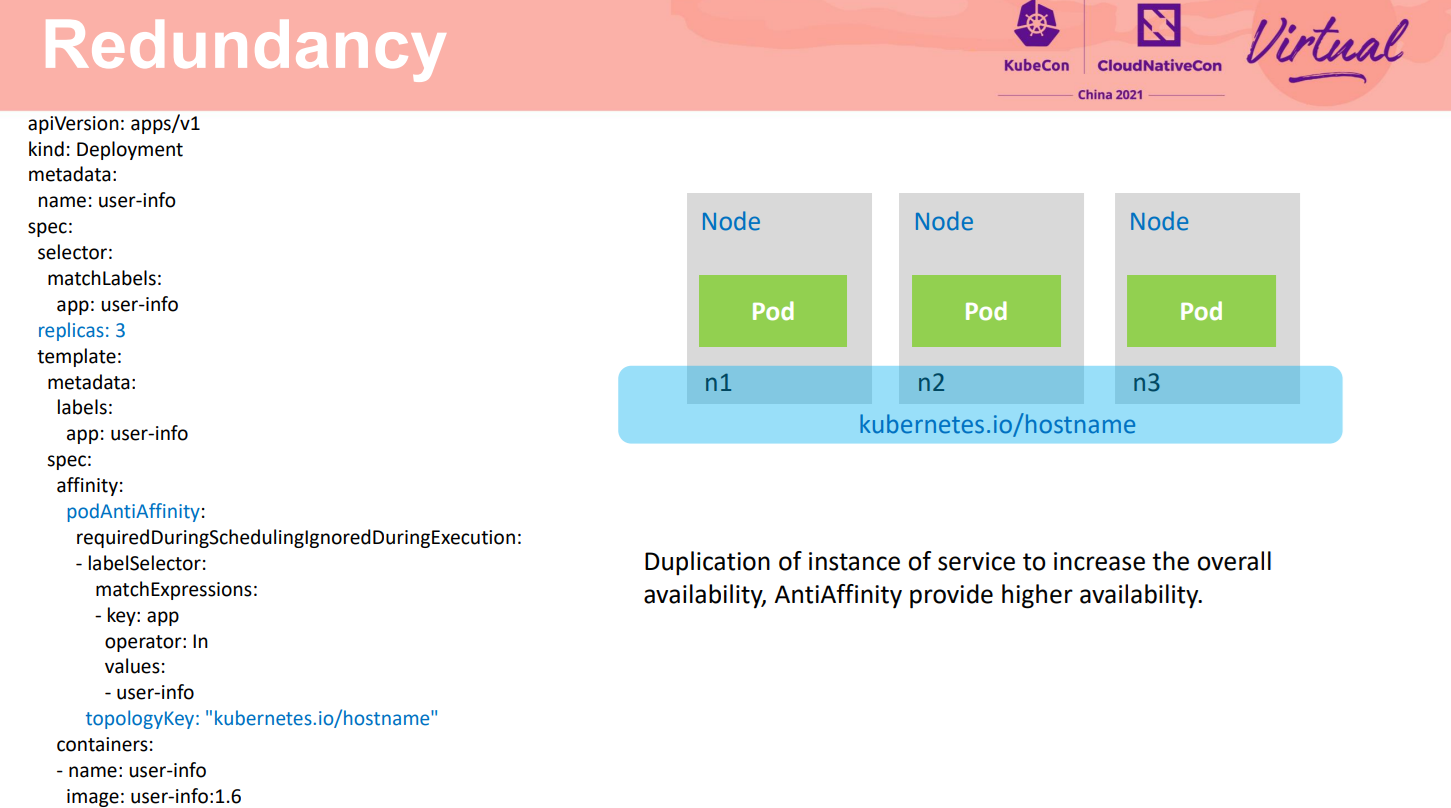
通过适当冗余来提高系统可用性是一个非常通用的实践。早期修建桥梁,桥墩底下的钻孔桩个数一般都会要求比力学核算的个数多好几个。在计算机世界中,这个理论更是随处可见。如**微服务部署多实例部署除了负载分担外,另外一个重要的用途就是提供适当的冗余,部分实例故障服务还是可用。**在云原生场景下,基于容器可以非常容易的对负载配置反亲和策略,将不同的实例部署在不同的节点,或者不同可用区的节点上。当某个可用区或者某个节点故障时,不影响最终业务,从而最大化的减少资源故障对服务整体的可用性影响。
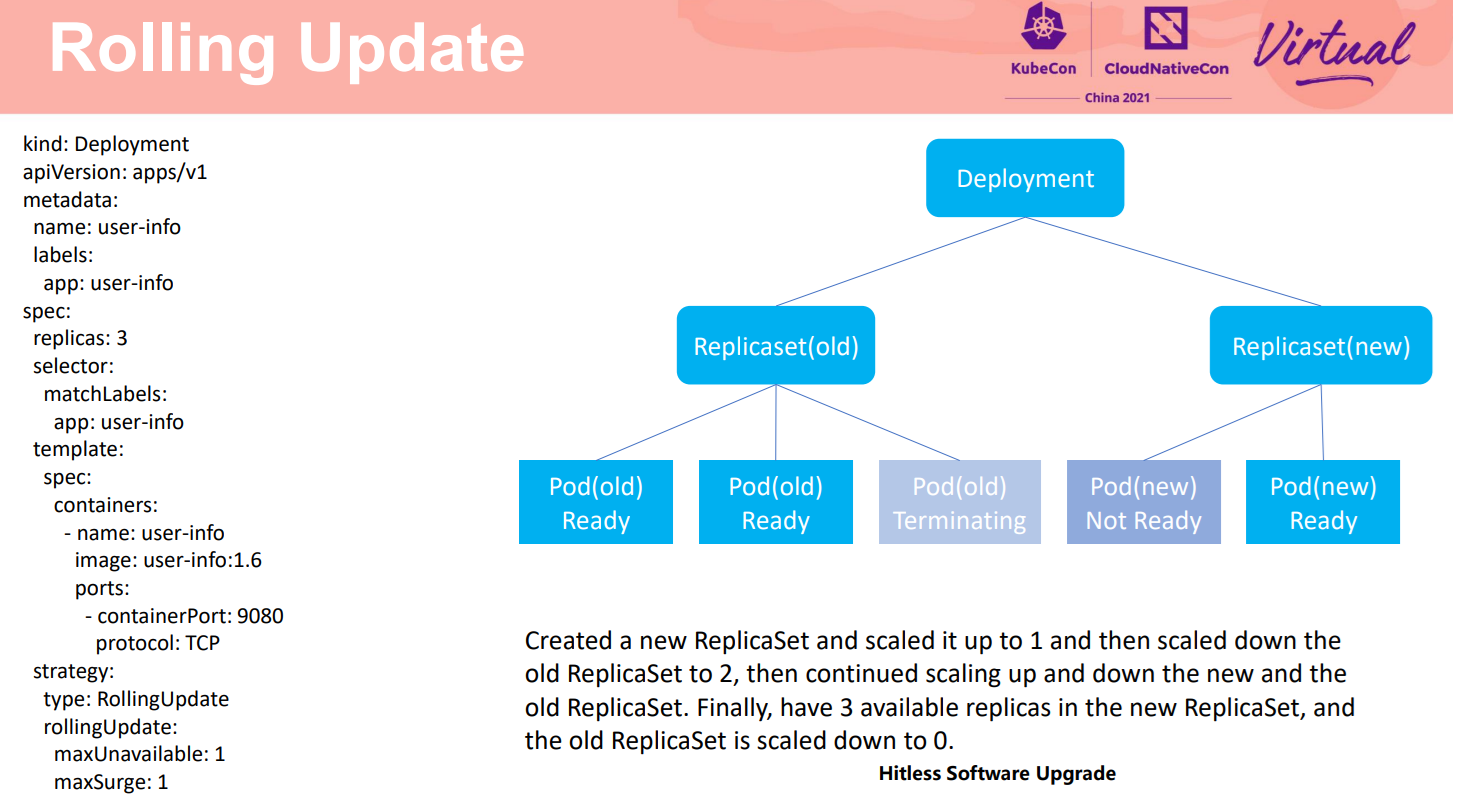
服务可靠性另外一个重要要求是减少升级过程对用户业务的影响,或者尽量保持业务不中断,对用户无感知。在我们提供的云原生解决方案中,Kubernetes滚动升级过程中,根据新版本的镜像先创建一定数据量的实例,然后逐步停用老的实例,滚动的完成新实例替换老实例的过程。在这个示例中,当服务配置了滚动升级策略,则在升级过程中就会滚动的先创建一个新实例,停用一个旧实例,然后再创建一个新实例,停用另外一个旧实例,最终创建3个新的实例,老的实例都逐步停用。
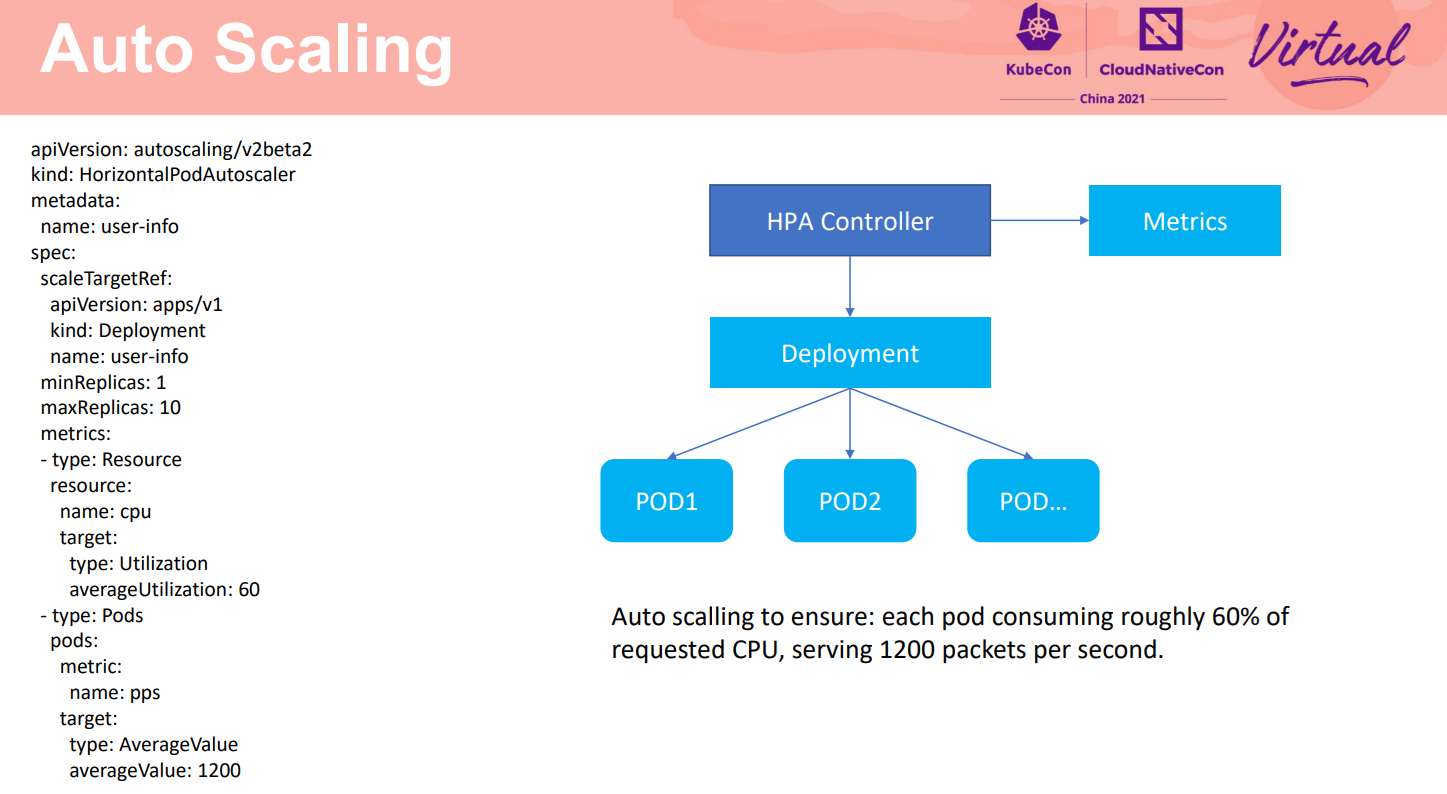
保证系统韧性的另外一个重要方面是在系统过载时能及时扩容。基于K8s提供的HPA,可以基于观测的指标变化自动的扩展实例。如实例中,当检测到CPU或者PPS高时,会自动的扩展服务实例,保证负载的CPU不高于60%,PPS不超过1200. 对于网格管理的服务间访问,通过非侵入方式收集服务的吞吐和延时,可以支持基于这些请求指标进行自动扩缩容,保证用户服务的访问质量。
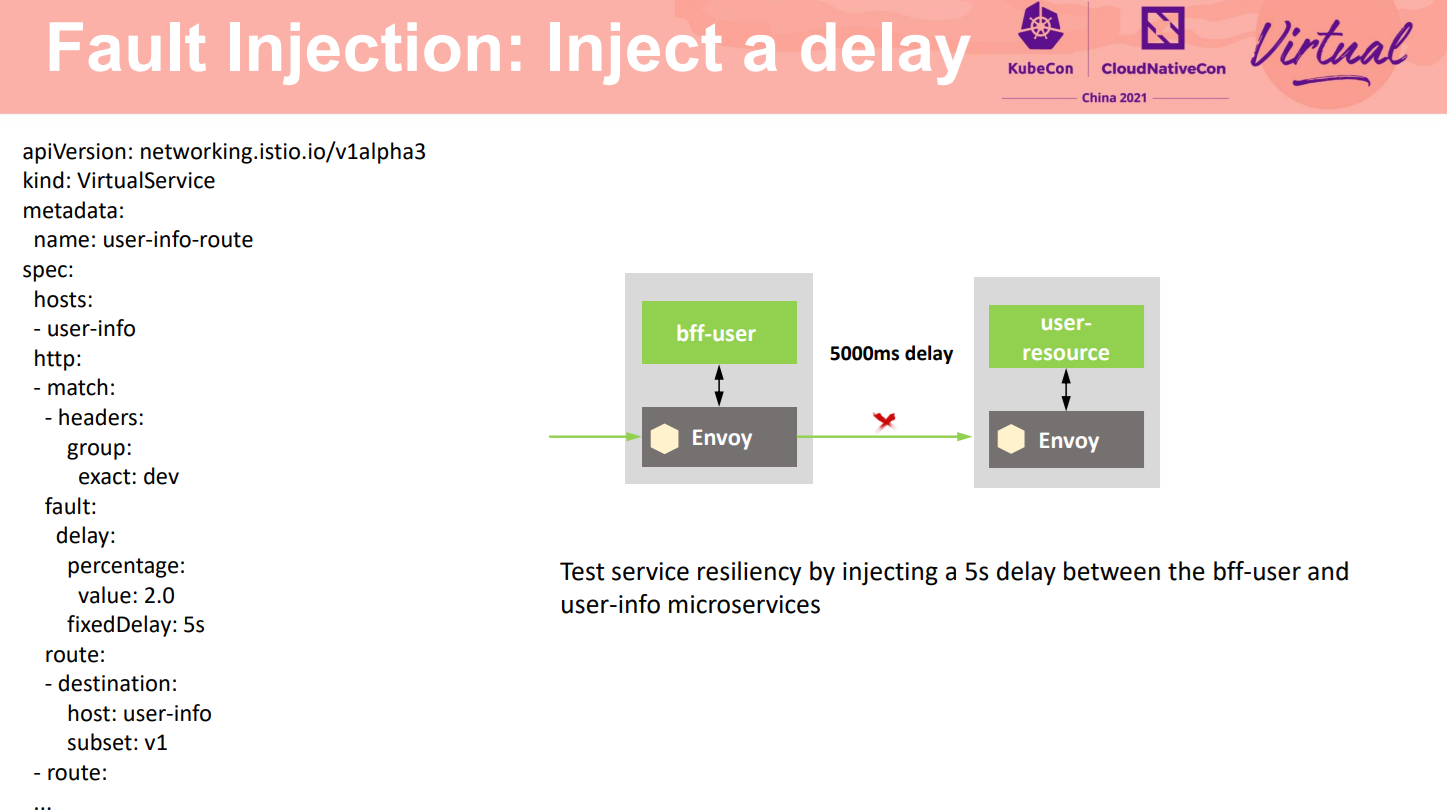
故障注入是一种评估系统可靠性的有效方法,通过向系统注入在实际应用中可能发生的故障,观察系统功能性能变化,故障检测、定位、隔离以及故障恢复情况,发现产品缺陷。
Istio提供了非侵入的额故障注入能力,无需修改业务代码,而是在网格中对特定的应用层协议进行故障注入,模拟出应用的故障场景。如所示,可以对某种请求注入5秒的延时,验证frontend程序对这种情况的处理。
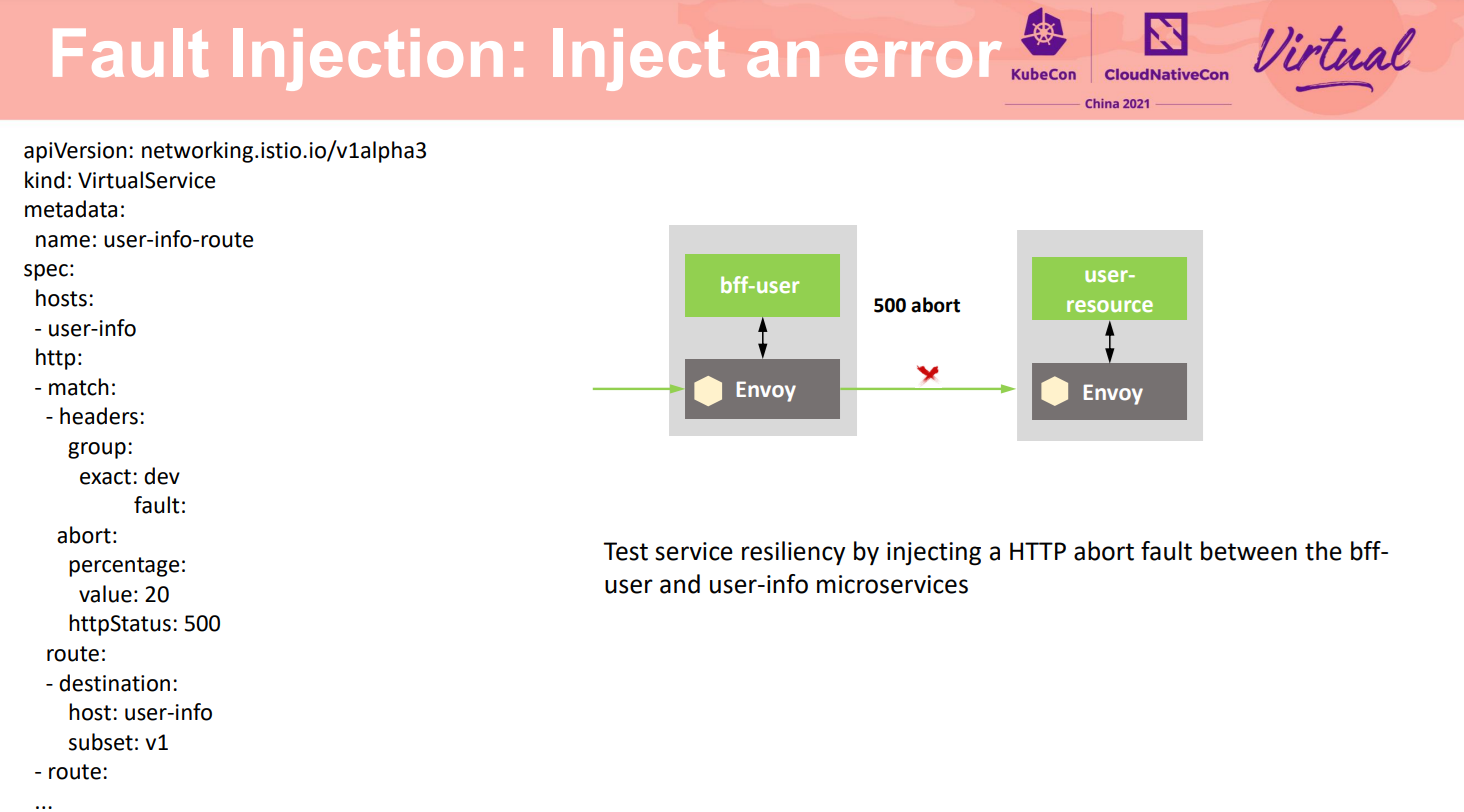
另外也可以注入一个特定的故障,测试服务在上游服务故障时能否最大化的保证业务可用,体现系统在业务实现上韧性满足要求。如所示,可以对某种请求注入一个指定的HTTP Code,如此对于访问的客户端来说,就与服务端发生异常一样。
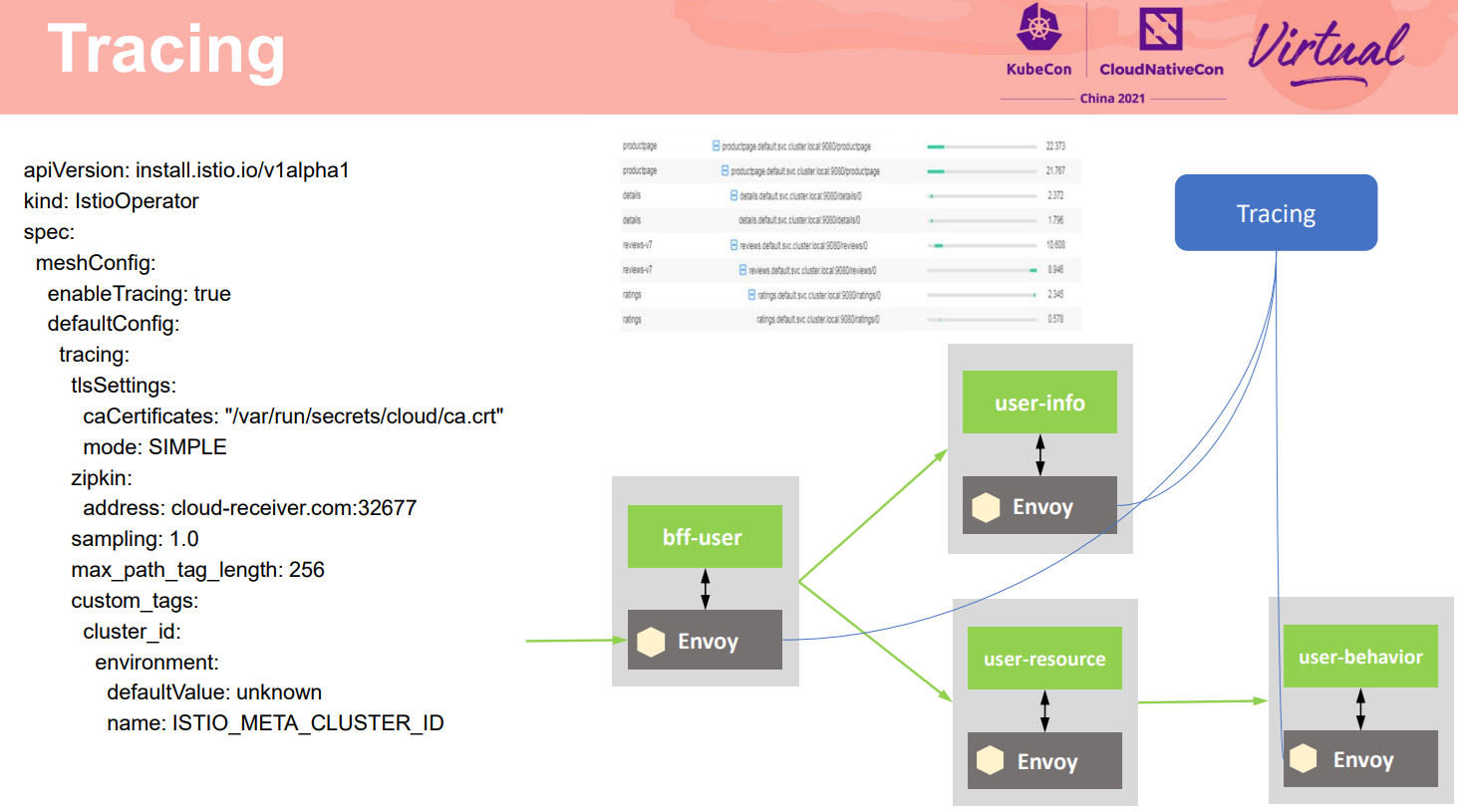
除了上面介绍的手段外,故障策略中最基础的是发现故障。调用链正是应对和解决大规模复杂的分布式系统在运行中遇到故障定位问题的一个有效手段。不同于早期的调用链,大部分是提供埋点的SDK让用户选择在自己的代码中进行调用链埋点,和网格结合后,这部分复杂的埋点在网格数据面完成。对使用者更简单,只要通过适当配置,就可以生成详细的调用链信息,对服务间的调用进行管理。
