【hadoop代码笔记】Hadoop作业提交之Child启动reduce任务
一、概要描述
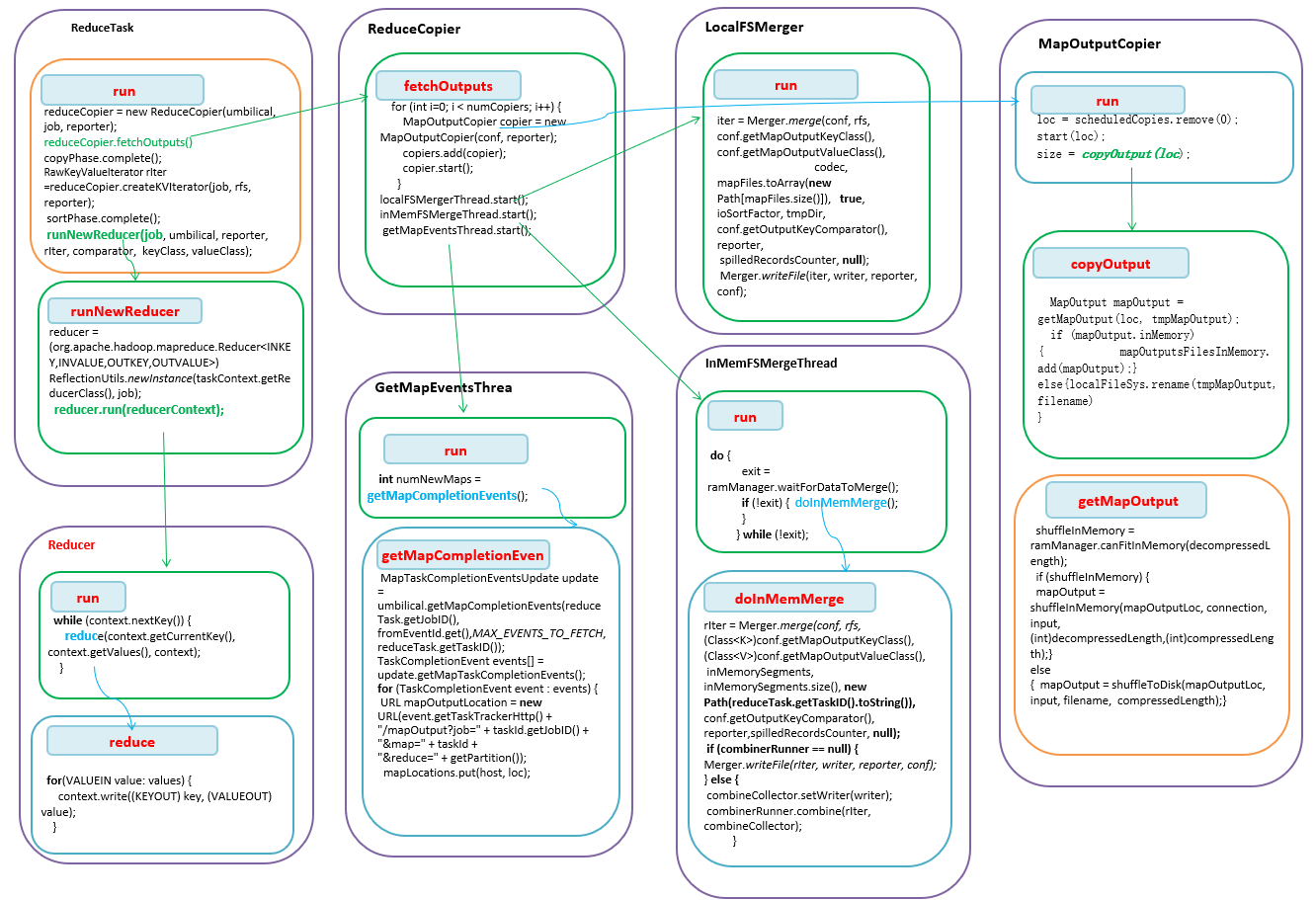
在上篇博文描述了TaskTracker启动一个独立的java进程来执行Map任务。接上上篇文章,TaskRunner线程执行中,会构造一个java –D** Child address port tasked这样第一个java命令,单独启动一个java进程。在Child的main函数中通过TaskUmbilicalProtocol协议,从TaskTracker获得需要执行的Task,并调用Task的run方法来执行。在ReduceTask而Task的run方法会通过java反射机制构造Reducer,Reducer.Context,然后调用构造的Reducer的run方法执行reduce操作。不同于map任务,在执行reduce任务前,需要把map的输出从map运行的tasktracker上拷贝到reducer运行的tasktracker上。
Reduce需要集群上若干个map任务的输出作为其特殊的分区文件。每个map任务完成的时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。这就是reduce任务的**复制阶段。**其实是启动若干个MapOutputCopier线程来复制完所有map输出。在复制完成后reduce任务进入排序阶段。这个阶段将由LocalFSMerger或InMemFSMergeThread合并map输出,维持其顺序排序。【即对有序的几个文件进行归并,采用归并排序】在reduce阶段,对已排序输出的每个键都要调用reduce函数,此阶段的输出直接写到文件系统,一般为HDFS上。(如果采用HDFS,由于tasktracker节点也是DataNoe,所以第一个块副本将被写到本地磁盘。 即数据本地化)
Map 任务完成后,会通知其父tasktracker状态更新,然后tasktracker通知jobtracker。通过心跳机制来完成。因此jobtracker知道map输出和tasktracker之间的映射关系。Reducer的一个getMapCompletionEvents线程定期询问jobtracker以便获取map输出位置。
二、 流程描述
-
在ReduceTak中 构建ReduceCopier对象,调用其fetchOutputs方法。
-
在ReduceCopier的fetchOutputs方法中分别构造几个独立的线程。相互配合,并分别独立的完成任务。
2.1 GetMapEventsThread线程通过RPC询问TaskTracker,对每个完成的Event,获取maptask所在的服务器地址,即MapTask输出的地址,构造URL,加入到mapLocations,供copier线程获取。
2.2构造并启动若干个MapOutputCopier线程,通过http协议,把map的输出从远端服务器拷贝的本地,如果可以放在内存中,则存储在内存中调用,否则保存在本地文件。
2.3LocalFSMerger对磁盘上的map 输出进行归并。
2.4nMemFSMergeThread对内存中的map输出进行归并。
3.根据拷贝到的map输出构造一个raw keyvalue的迭代器,作为reduce的输入。
-
调用runNewReducer方法中根据配置的Reducer类构造一个Reducer实例和运行的上下文。并调用reducer的run方法来执行到用户定义的reduce操作。。
-
在Reducer的run方法中从上下文中取出一个key和该key对应的Value集合(Iterable
类型),调用reducer的reduce方法进行处理。 -
Recuer的reduce方法是用户定义的处理数据的方法,也是用户唯一需要定义的方法。
三、代码详细
1. Child的main方法每个task进程都会被在单独的进程中执行,这个方法就是这些进程的入口方法。Reduce和map一样都是由该main函数调用。所以此处不做描述,详细见上节Child启动map任务。
**2. ReduceTask的run方法。**在Child子进程中被调用,执行用户定义的Reduce操作。前面代码逻辑和MapTask类似。通过TaskUmbilicalProtocol向tasktracker上报执行进度。开启线程向TaskTracker上报进度,根据task的不同动作要求执行不同的方法,如jobClean,jobsetup,taskCleanup。对于部分的了解可以产看taskTracker获取Task文章中的 JobTracker的 heartbeat方法处的详细解释。不同于map任务,在执行reduce任务前,需要把map的输出从map运行的tasktracker上拷贝到reducer运行的tasktracker上。
1@SuppressWarnings("unchecked")
2 public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
3 throws IOException, InterruptedException, ClassNotFoundException {
4 job.setBoolean("mapred.skip.on", isSkipping());
5
6 if (isMapOrReduce()) {
7 copyPhase = getProgress().addPhase("copy");
8 sortPhase = getProgress().addPhase("sort");
9 reducePhase = getProgress().addPhase("reduce");
10 }
11 // start thread that will handle communication with parent
12 TaskReporter reporter = new TaskReporter(getProgress(), umbilical);
13 reporter.startCommunicationThread();
14 boolean useNewApi = job.getUseNewReducer();
15 initialize(job, getJobID(), reporter, useNewApi);
16
17 // check if it is a cleanupJobTask
18 if (jobCleanup) {
19 runJobCleanupTask(umbilical, reporter);
20 return;
21 }
22 if (jobSetup) {
23 runJobSetupTask(umbilical, reporter);
24 return;
25 }
26 if (taskCleanup) {
27 runTaskCleanupTask(umbilical, reporter);
28 return;
29 }
30
31 // Initialize the codec
32 codec = initCodec();
33
34 boolean isLocal = "local".equals(job.get("mapred.job.tracker", "local"));
35
36 //如果不是一个本地执行额模式(就是配置中不是分布式的),则要启动一个ReduceCopier来拷贝Map的输出,即Reduce的输入。
37 if (!isLocal) {
38 reduceCopier = new ReduceCopier(umbilical, job, reporter);
39 if (!reduceCopier.fetchOutputs()) {
40 if(reduceCopier.mergeThrowable instanceof FSError) {
41 LOG.error("Task: " + getTaskID() + " - FSError: " +
42 StringUtils.stringifyException(reduceCopier.mergeThrowable));
43 umbilical.fsError(getTaskID(),
44 reduceCopier.mergeThrowable.getMessage());
45 }
46 throw new IOException("Task: " + getTaskID() +
47 " - The reduce copier failed", reduceCopier.mergeThrowable);
48 }
49 }
50 copyPhase.complete();
51 //拷贝完成后,进入sort阶段。
52 setPhase(TaskStatus.Phase.SORT);
53 statusUpdate(umbilical);
54
55 final FileSystem rfs = FileSystem.getLocal(job).getRaw();
56 RawKeyValueIterator rIter = isLocal
57 ? Merger.merge(job, rfs, job.getMapOutputKeyClass(),
58 job.getMapOutputValueClass(), codec, getMapFiles(rfs, true),
59 !conf.getKeepFailedTaskFiles(), job.getInt("io.sort.factor", 100),
60 new Path(getTaskID().toString()), job.getOutputKeyComparator(),
61 reporter, spilledRecordsCounter, null)
62 : reduceCopier.createKVIterator(job, rfs, reporter);
63
64 // free up the data structures
65 mapOutputFilesOnDisk.clear();
66
67 sortPhase.complete(); // sort is complete
68 setPhase(TaskStatus.Phase.REDUCE);
69 statusUpdate(umbilical);
70 Class keyClass = job.getMapOutputKeyClass();
71 Class valueClass = job.getMapOutputValueClass();
72 RawComparator comparator = job.getOutputValueGroupingComparator();
73
74 if (useNewApi) {
75 runNewReducer(job, umbilical, reporter, rIter, comparator,
76 keyClass, valueClass);
77 } else {
78 runOldReducer(job, umbilical, reporter, rIter, comparator,
79 keyClass, valueClass);
80 }
81 done(umbilical, reporter);
82 }
- ReduceCopier类的fetchOutputs方法。该方法负责将map的输出拷贝的reduce端进程处理。从代码上看,启动了一个LocalFSMerger、InMemFSMergeThread、 GetMapEventsThread 和若干个MapOutputCopier线程。几个独立的线程。相互配合,并分别独立的完成任务。
1public boolean fetchOutputs() throws IOException {
2 int totalFailures = 0;
3 int numInFlight = 0, numCopied = 0;
4 DecimalFormat mbpsFormat = new DecimalFormat("0.00");
5 final Progress copyPhase =
6 reduceTask.getProgress().phase();
7 LocalFSMerger localFSMergerThread = null;
8 InMemFSMergeThread inMemFSMergeThread = null;
9 GetMapEventsThread getMapEventsThread = null;
10
11
12 for (int i = 0; i < numMaps; i++) {
13 copyPhase.addPhase(); // add sub-phase per file
14 }
15
16 //1)根据配置的numCopiers数量构造若干个MapOutputCopier拷贝线程,默认是5个,正是这些MapOutputCopier来实施的拷贝任务。
17 copiers = new ArrayList<MapOutputCopier>(numCopiers);
18
19 // start all the copying threads
20 for (int i=0; i < numCopiers; i++) {
21 MapOutputCopier copier = new MapOutputCopier(conf, reporter);
22 copiers.add(copier);
23
24 copier.start();
25 }
26
27 //start the on-disk-merge thread 2)启动磁盘merge线程(参照后面方法)
28 localFSMergerThread = new LocalFSMerger((LocalFileSystem)localFileSys);
29 //start the in memory merger thread 3)启动内存merge线程(参照后面方法)
30 inMemFSMergeThread = new InMemFSMergeThread();
31 localFSMergerThread.start();
32 inMemFSMergeThread.start();
33
34 // start the map events thread 4)启动merge事件获取线程
35 getMapEventsThread = new GetMapEventsThread();
36 getMapEventsThread.start();
37
38 // start the clock for bandwidth measurement
39 long startTime = System.currentTimeMillis();
40 long currentTime = startTime;
41 long lastProgressTime = startTime;
42 long lastOutputTime = 0;
43
44 // loop until we get all required outputs
45 //5)当获取到的copiedMapOutputs数量小于map数时,说明还没有拷贝完成,则一直执行。在执行中会根据时间进度一直打印输出,表示已经拷贝了多少个map的输出,还有多万未完成。
46 while (copiedMapOutputs.size() < numMaps && mergeThrowable == null) {
47
48 currentTime = System.currentTimeMillis();
49 boolean logNow = false;
50 if (currentTime - lastOutputTime > MIN_LOG_TIME) {
51 lastOutputTime = currentTime;
52 logNow = true;
53 }
54 if (logNow) {
55 LOG.info(reduceTask.getTaskID() + " Need another "
56 + (numMaps - copiedMapOutputs.size()) + " map output(s) "
57 + "where " + numInFlight + " is already in progress");
58 }
59
60 // Put the hash entries for the failed fetches.
61 Iterator<MapOutputLocation> locItr = retryFetches.iterator();
62
63 while (locItr.hasNext()) {
64 MapOutputLocation loc = locItr.next();
65 List<MapOutputLocation> locList =
66 mapLocations.get(loc.getHost());
67
68 // Check if the list exists. Map output location mapping is cleared
69 // once the jobtracker restarts and is rebuilt from scratch.
70 // Note that map-output-location mapping will be recreated and hence
71 // we continue with the hope that we might find some locations
72 // from the rebuild map.
73 if (locList != null) {
74 // Add to the beginning of the list so that this map is
75 //tried again before the others and we can hasten the
76 //re-execution of this map should there be a problem
77 locList.add(0, loc);
78 }
79 }
80
81 if (retryFetches.size() > 0) {
82 LOG.info(reduceTask.getTaskID() + ": " +
83 "Got " + retryFetches.size() +
84 " map-outputs from previous failures");
85 }
86 // clear the "failed" fetches hashmap
87 retryFetches.clear();
88
89 // now walk through the cache and schedule what we can
90 int numScheduled = 0;
91 int numDups = 0;
92
93 synchronized (scheduledCopies) {
94
95 // Randomize the map output locations to prevent
96 // all reduce-tasks swamping the same tasktracker
97 List<String> hostList = new ArrayList<String>();
98 hostList.addAll(mapLocations.keySet());
99
100 Collections.shuffle(hostList, this.random);
101
102 Iterator<String> hostsItr = hostList.iterator();
103
104 while (hostsItr.hasNext()) {
105
106 String host = hostsItr.next();
107
108 List<MapOutputLocation> knownOutputsByLoc =
109 mapLocations.get(host);
110
111 // Check if the list exists. Map output location mapping is
112 // cleared once the jobtracker restarts and is rebuilt from
113 // scratch.
114 // Note that map-output-location mapping will be recreated and
115 // hence we continue with the hope that we might find some
116 // locations from the rebuild map and add then for fetching.
117 if (knownOutputsByLoc == null || knownOutputsByLoc.size() == 0) {
118 continue;
119 }
120
121 //Identify duplicate hosts here
122 if (uniqueHosts.contains(host)) {
123 numDups += knownOutputsByLoc.size();
124 continue;
125 }
126
127 Long penaltyEnd = penaltyBox.get(host);
128 boolean penalized = false;
129
130 if (penaltyEnd != null) {
131 if (currentTime < penaltyEnd.longValue()) {
132 penalized = true;
133 } else {
134 penaltyBox.remove(host);
135 }
136 }
137
138 if (penalized)
139 continue;
140
141 synchronized (knownOutputsByLoc) {
142
143 locItr = knownOutputsByLoc.iterator();
144
145 while (locItr.hasNext()) {
146
147 MapOutputLocation loc = locItr.next();
148
149 // Do not schedule fetches from OBSOLETE maps
150 if (obsoleteMapIds.contains(loc.getTaskAttemptId())) {
151 locItr.remove();
152 continue;
153 }
154
155 uniqueHosts.add(host);
156 scheduledCopies.add(loc);
157 locItr.remove(); // remove from knownOutputs
158 numInFlight++; numScheduled++;
159
160 break; //we have a map from this host
161 }
162 }
163 }
164 scheduledCopies.notifyAll();
165 }
166
167 if (numScheduled > 0 || logNow) {
168 LOG.info(reduceTask.getTaskID() + " Scheduled " + numScheduled +
169 " outputs (" + penaltyBox.size() +
170 " slow hosts and" + numDups + " dup hosts)");
171 }
172
173 if (penaltyBox.size() > 0 && logNow) {
174 LOG.info("Penalized(slow) Hosts: ");
175 for (String host : penaltyBox.keySet()) {
176 LOG.info(host + " Will be considered after: " +
177 ((penaltyBox.get(host) - currentTime)/1000) + " seconds.");
178 }
179 }
180
181 // if we have no copies in flight and we can't schedule anything
182 // new, just wait for a bit
183 try {
184 if (numInFlight == 0 && numScheduled == 0) {
185 // we should indicate progress as we don't want TT to think
186 // we're stuck and kill us
187 reporter.progress();
188 Thread.sleep(5000);
189 }
190 } catch (InterruptedException e) { } // IGNORE
191
192 while (numInFlight > 0 && mergeThrowable == null) {
193 LOG.debug(reduceTask.getTaskID() + " numInFlight = " +
194 numInFlight);
195 //the call to getCopyResult will either
196 //1) return immediately with a null or a valid CopyResult object,
197 // or
198 //2) if the numInFlight is above maxInFlight, return with a
199 // CopyResult object after getting a notification from a
200 // fetcher thread,
201 //So, when getCopyResult returns null, we can be sure that
202 //we aren't busy enough and we should go and get more mapcompletion
203 //events from the tasktracker
204 CopyResult cr = getCopyResult(numInFlight);
205
206 if (cr == null) {
207 break;
208 }
209
210 if (cr.getSuccess()) { // a successful copy
211 numCopied++;
212 lastProgressTime = System.currentTimeMillis();
213 reduceShuffleBytes.increment(cr.getSize());
214
215 long secsSinceStart =
216 (System.currentTimeMillis()-startTime)/1000+1;
217 float mbs = ((float)reduceShuffleBytes.getCounter())/(1024*1024);
218 float transferRate = mbs/secsSinceStart;
219
220 copyPhase.startNextPhase();
221 copyPhase.setStatus("copy (" + numCopied + " of " + numMaps
222 + " at " +
223 mbpsFormat.format(transferRate) + " MB/s)");
224
225 // Note successful fetch for this mapId to invalidate
226 // (possibly) old fetch-failures
227 fetchFailedMaps.remove(cr.getLocation().getTaskId());
228 } else if (cr.isObsolete()) {
229 //ignore
230 LOG.info(reduceTask.getTaskID() +
231 " Ignoring obsolete copy result for Map Task: " +
232 cr.getLocation().getTaskAttemptId() + " from host: " +
233 cr.getHost());
234 } else {
235 retryFetches.add(cr.getLocation());
236
237 // note the failed-fetch
238 TaskAttemptID mapTaskId = cr.getLocation().getTaskAttemptId();
239 TaskID mapId = cr.getLocation().getTaskId();
240
241 totalFailures++;
242 Integer noFailedFetches =
243 mapTaskToFailedFetchesMap.get(mapTaskId);
244 noFailedFetches =
245 (noFailedFetches == null) ? 1 : (noFailedFetches + 1);
246 mapTaskToFailedFetchesMap.put(mapTaskId, noFailedFetches);
247 LOG.info("Task " + getTaskID() + ": Failed fetch #" +
248 noFailedFetches + " from " + mapTaskId);
249
250 // did the fetch fail too many times?
251 // using a hybrid technique for notifying the jobtracker.
252 // a. the first notification is sent after max-retries
253 // b. subsequent notifications are sent after 2 retries.
254 if ((noFailedFetches >= maxFetchRetriesPerMap)
255 && ((noFailedFetches - maxFetchRetriesPerMap) % 2) == 0) {
256 synchronized (ReduceTask.this) {
257 taskStatus.addFetchFailedMap(mapTaskId);
258 LOG.info("Failed to fetch map-output from " + mapTaskId +
259 " even after MAX_FETCH_RETRIES_PER_MAP retries... "
260 + " reporting to the JobTracker");
261 }
262 }
263 // note unique failed-fetch maps
264 if (noFailedFetches == maxFetchRetriesPerMap) {
265 fetchFailedMaps.add(mapId);
266
267 // did we have too many unique failed-fetch maps?
268 // and did we fail on too many fetch attempts?
269 // and did we progress enough
270 // or did we wait for too long without any progress?
271
272 // check if the reducer is healthy
273 boolean reducerHealthy =
274 (((float)totalFailures / (totalFailures + numCopied))
275 < MAX_ALLOWED_FAILED_FETCH_ATTEMPT_PERCENT);
276
277 // check if the reducer has progressed enough
278 boolean reducerProgressedEnough =
279 (((float)numCopied / numMaps)
280 >= MIN_REQUIRED_PROGRESS_PERCENT);
281
282 // check if the reducer is stalled for a long time
283 // duration for which the reducer is stalled
284 int stallDuration =
285 (int)(System.currentTimeMillis() - lastProgressTime);
286 // duration for which the reducer ran with progress
287 int shuffleProgressDuration =
288 (int)(lastProgressTime - startTime);
289 // min time the reducer should run without getting killed
290 int minShuffleRunDuration =
291 (shuffleProgressDuration > maxMapRuntime)
292 ? shuffleProgressDuration
293 : maxMapRuntime;
294 boolean reducerStalled =
295 (((float)stallDuration / minShuffleRunDuration)
296 >= MAX_ALLOWED_STALL_TIME_PERCENT);
297
298 // kill if not healthy and has insufficient progress
299 if ((fetchFailedMaps.size() >= maxFailedUniqueFetches ||
300 fetchFailedMaps.size() == (numMaps - copiedMapOutputs.size()))
301 && !reducerHealthy
302 && (!reducerProgressedEnough || reducerStalled)) {
303 LOG.fatal("Shuffle failed with too many fetch failures " +
304 "and insufficient progress!" +
305 "Killing task " + getTaskID() + ".");
306 umbilical.shuffleError(getTaskID(),
307 "Exceeded MAX_FAILED_UNIQUE_FETCHES;"
308 + " bailing-out.");
309 }
310 }
311
312 // back off exponentially until num_retries <= max_retries
313 // back off by max_backoff/2 on subsequent failed attempts
314 currentTime = System.currentTimeMillis();
315 int currentBackOff = noFailedFetches <= maxFetchRetriesPerMap
316 ? BACKOFF_INIT
317 * (1 << (noFailedFetches - 1))
318 : (this.maxBackoff * 1000 / 2);
319 penaltyBox.put(cr.getHost(), currentTime + currentBackOff);
320 LOG.warn(reduceTask.getTaskID() + " adding host " +
321 cr.getHost() + " to penalty box, next contact in " +
322 (currentBackOff/1000) + " seconds");
323 }
324 uniqueHosts.remove(cr.getHost());
325 numInFlight--;
326 }
327 }
328
329 // all done, inform the copiers to exit
330 exitGetMapEvents= true;
331 try {
332 getMapEventsThread.join();
333 LOG.info("getMapsEventsThread joined.");
334 } catch (Throwable t) {
335 LOG.info("getMapsEventsThread threw an exception: " +
336 StringUtils.stringifyException(t));
337 }
338
339 synchronized (copiers) {
340 synchronized (scheduledCopies) {
341 for (MapOutputCopier copier : copiers) {
342 copier.interrupt();
343 }
344 copiers.clear();
345 }
346 }
347
348 // copiers are done, exit and notify the waiting merge threads
349 synchronized (mapOutputFilesOnDisk) {
350 exitLocalFSMerge = true;
351 mapOutputFilesOnDisk.notify();
352 }
353
354 ramManager.close();
355
356 //Do a merge of in-memory files (if there are any)
357 if (mergeThrowable == null) {
358 try {
359 // Wait for the on-disk merge to complete
360 localFSMergerThread.join();
361 LOG.info("Interleaved on-disk merge complete: " +
362 mapOutputFilesOnDisk.size() + " files left.");
363
364 //wait for an ongoing merge (if it is in flight) to complete
365 inMemFSMergeThread.join();
366 LOG.info("In-memory merge complete: " +
367 mapOutputsFilesInMemory.size() + " files left.");
368 } catch (Throwable t) {
369 LOG.warn(reduceTask.getTaskID() +
370 " Final merge of the inmemory files threw an exception: " +
371 StringUtils.stringifyException(t));
372 // check if the last merge generated an error
373 if (mergeThrowable != null) {
374 mergeThrowable = t;
375 }
376 return false;
377 }
378 }
379 return mergeThrowable == null && copiedMapOutputs.size() == numMaps;
380 }
- MapOutputCopier线程的run方法。从scheduledCopies(List
)中取出对象来调用copyOutput方法执行拷贝。通过http协议,把map的输出从远端服务器拷贝的本地,如果可以放在内存中,则存储在内存中调用,否则保存在本地文件。
1public void run() {
2 while (true) {
3 MapOutputLocation loc = null;
4 long size = -1;
5 synchronized (scheduledCopies) {
6 while (scheduledCopies.isEmpty()) {
7 scheduledCopies.wait();
8 }
9 loc = scheduledCopies.remove(0);
10 }
11
12 start(loc);
13 size = copyOutput(loc);
14
15
16 if (decompressor != null) {
17 CodecPool.returnDecompressor(decompressor);
18 }
19
20 }
5.MapOutputCopier线程的copyOutput方法。map的输出从远端map所在的tasktracker拷贝到reducer任务所在的tasktracker。
1private long copyOutput(MapOutputLocation loc
2 ) throws IOException, InterruptedException {
3 // 从拷贝的记录中检查是否已经拷贝完成。
4 if (copiedMapOutputs.contains(loc.getTaskId()) ||
5 obsoleteMapIds.contains(loc.getTaskAttemptId())) {
6 return CopyResult.OBSOLETE;
7 }
8 TaskAttemptID reduceId = reduceTask.getTaskID();
9 Path filename = new Path("/" + TaskTracker.getIntermediateOutputDir(
10 reduceId.getJobID().toString(),
11 reduceId.toString())
12 + "/map_" +
13 loc.getTaskId().getId() + ".out");
14
15 //一个拷贝map输出的临时文件。
16 Path tmpMapOutput = new Path(filename+"-"+id);
17
18 //拷贝map输出。
19 MapOutput mapOutput = getMapOutput(loc, tmpMapOutput);
20 if (mapOutput == null) {
21 throw new IOException("Failed to fetch map-output for " +
22 loc.getTaskAttemptId() + " from " +
23 loc.getHost());
24 }
25 // The size of the map-output
26 long bytes = mapOutput.compressedSize;
27
28 synchronized (ReduceTask.this) {
29 if (copiedMapOutputs.contains(loc.getTaskId())) {
30 mapOutput.discard();
31 return CopyResult.OBSOLETE;
32 }
33 // Note that we successfully copied the map-output
34 noteCopiedMapOutput(loc.getTaskId());
35 return bytes;
36 }
37
38 // 处理map的输出,如果是存储在内存中则添加到(Collections.synchronizedList(new LinkedList<MapOutput>)类型的结合mapOutputsFilesInMemory中,否则如果存储在临时文件中,则冲明明临时文件为正式的输出文件。
39 if (mapOutput.inMemory) {
40 // Save it in the synchronized list of map-outputs
41 mapOutputsFilesInMemory.add(mapOutput);
42 } else {
43
44 tmpMapOutput = mapOutput.file;
45 filename = new Path(tmpMapOutput.getParent(), filename.getName());
46 if (!localFileSys.rename(tmpMapOutput, filename)) {
47 localFileSys.delete(tmpMapOutput, true);
48 bytes = -1;
49 throw new IOException("Failed to rename map output " +
50 tmpMapOutput + " to " + filename);
51 }
52
53 synchronized (mapOutputFilesOnDisk) {
54 addToMapOutputFilesOnDisk(localFileSys.getFileStatus(filename));
55 }
56 }
57
58 // Note that we successfully copied the map-output
59 noteCopiedMapOutput(loc.getTaskId());
60 }
61
62 return bytes;
63}
6.ReduceTask.ReduceCopier.MapOutputCopier的shuffleInMemory方法。根据上一方法当map的输出可以在内存中存储时会调用该方法。
1private MapOutput shuffleInMemory(MapOutputLocation mapOutputLoc,
2 URLConnection connection,
3 InputStream input,
4 int mapOutputLength,
5 int compressedLength)
6 throws IOException, InterruptedException {
7
8 //checksum 输入流,读Mpareduce中间文件IFile.
9 IFileInputStream checksumIn =
10 new IFileInputStream(input,compressedLength);
11
12 input = checksumIn;
13
14 // 如果加密,则根据codec来构建一个解密的输入流。
15 if (codec != null) {
16 decompressor.reset();
17 input = codec.createInputStream(input, decompressor);
18 }
19
20 //把map的输出拷贝到内存的buffer中。
21 byte[] shuffleData = new byte[mapOutputLength];
22 MapOutput mapOutput =
23 new MapOutput(mapOutputLoc.getTaskId(),
24 mapOutputLoc.getTaskAttemptId(), shuffleData, compressedLength);
25
26 int bytesRead = 0;
27 try {
28 int n = input.read(shuffleData, 0, shuffleData.length);
29 while (n > 0) {
30 bytesRead += n;
31 shuffleClientMetrics.inputBytes(n);
32
33 // indicate we're making progress
34 reporter.progress();
35 n = input.read(shuffleData, bytesRead,
36 (shuffleData.length-bytesRead));
37 }
38
39 LOG.info("Read " + bytesRead + " bytes from map-output for " +
40 mapOutputLoc.getTaskAttemptId());
41
42 input.close();
43 } catch (IOException ioe) {
44 LOG.info("Failed to shuffle from " + mapOutputLoc.getTaskAttemptId(),
45 ioe);
46
47 // Inform the ram-manager
48 ramManager.closeInMemoryFile(mapOutputLength);
49 ramManager.unreserve(mapOutputLength);
50
51 // Discard the map-output
52 try {
53 mapOutput.discard();
54 } catch (IOException ignored) {
55 LOG.info("Failed to discard map-output from " +
56 mapOutputLoc.getTaskAttemptId(), ignored);
57 }
58 mapOutput = null;
59
60 // Close the streams
61 IOUtils.cleanup(LOG, input);
62
63 // Re-throw
64 throw ioe;
65 }
66
67 // Close the in-memory file
68 ramManager.closeInMemoryFile(mapOutputLength);
69
70 // Sanity check
71 if (bytesRead != mapOutputLength) {
72 // Inform the ram-manager
73 ramManager.unreserve(mapOutputLength);
74
75 // Discard the map-output
76 try {
77 mapOutput.discard();
78 } catch (IOException ignored) {
79 // IGNORED because we are cleaning up
80 LOG.info("Failed to discard map-output from " +
81 mapOutputLoc.getTaskAttemptId(), ignored);
82 }
83 mapOutput = null;
84
85 throw new IOException("Incomplete map output received for " +
86 mapOutputLoc.getTaskAttemptId() + " from " +
87 mapOutputLoc.getOutputLocation() + " (" +
88 bytesRead + " instead of " +
89 mapOutputLength + ")"
90 );
91 }
92
93 // TODO: Remove this after a 'fix' for HADOOP-3647
94 if (mapOutputLength > 0) {
95 DataInputBuffer dib = new DataInputBuffer();
96 dib.reset(shuffleData, 0, shuffleData.length);
97 LOG.info("Rec #1 from " + mapOutputLoc.getTaskAttemptId() + " -> (" +
98 WritableUtils.readVInt(dib) + ", " +
99 WritableUtils.readVInt(dib) + ") from " +
100 mapOutputLoc.getHost());
101 }
102
103 return mapOutput;
104 }
7.ReduceTask.ReduceCopier.MapOutputCopier的shuffleToDisk 方法把map输出拷贝到本地磁盘。当map的输出不能再内存中存储时,调用该方法。
1private MapOutput shuffleToDisk(MapOutputLocation mapOutputLoc,
2 InputStream input,
3 Path filename,
4 long mapOutputLength)
5 throws IOException {
6 // Find out a suitable location for the output on local-filesystem
7 Path localFilename =
8 lDirAlloc.getLocalPathForWrite(filename.toUri().getPath(),
9 mapOutputLength, conf);
10
11 MapOutput mapOutput =
12 new MapOutput(mapOutputLoc.getTaskId(), mapOutputLoc.getTaskAttemptId(),
13 conf, localFileSys.makeQualified(localFilename),
14 mapOutputLength);
15
16
17 // Copy data to local-disk
18 OutputStream output = null;
19 long bytesRead = 0;
20 try {
21 output = rfs.create(localFilename);
22
23 byte[] buf = new byte[64 * 1024];
24 int n = input.read(buf, 0, buf.length);
25 while (n > 0) {
26 bytesRead += n;
27 shuffleClientMetrics.inputBytes(n);
28 output.write(buf, 0, n);
29
30 // indicate we're making progress
31 reporter.progress();
32 n = input.read(buf, 0, buf.length);
33 }
34
35 LOG.info("Read " + bytesRead + " bytes from map-output for " +
36 mapOutputLoc.getTaskAttemptId());
37
38 output.close();
39 input.close();
40 } catch (IOException ioe) {
41 LOG.info("Failed to shuffle from " + mapOutputLoc.getTaskAttemptId(),
42 ioe);
43
44 // Discard the map-output
45 try {
46 mapOutput.discard();
47 } catch (IOException ignored) {
48 LOG.info("Failed to discard map-output from " +
49 mapOutputLoc.getTaskAttemptId(), ignored);
50 }
51 mapOutput = null;
52
53 // Close the streams
54 IOUtils.cleanup(LOG, input, output);
55
56 // Re-throw
57 throw ioe;
58 }
59
60 // Sanity check
61 if (bytesRead != mapOutputLength) {
62 try {
63 mapOutput.discard();
64 } catch (Exception ioe) {
65 // IGNORED because we are cleaning up
66 LOG.info("Failed to discard map-output from " +
67 mapOutputLoc.getTaskAttemptId(), ioe);
68 } catch (Throwable t) {
69 String msg = getTaskID() + " : Failed in shuffle to disk :"
70 + StringUtils.stringifyException(t);
71 reportFatalError(getTaskID(), t, msg);
72 }
73 mapOutput = null;
74
75 throw new IOException("Incomplete map output received for " +
76 mapOutputLoc.getTaskAttemptId() + " from " +
77 mapOutputLoc.getOutputLocation() + " (" +
78 bytesRead + " instead of " +
79 mapOutputLength + ")"
80 );
81 }
82
83 return mapOutput;
84
85 }
8.LocalFSMerger线程的run方法。Merge map输出的本地拷贝。
1public void run() {
2 try {
3 LOG.info(reduceTask.getTaskID() + " Thread started: " + getName());
4 while(!exitLocalFSMerge){
5 // TreeSet<FileStatus>(mapOutputFileComparator)中存储了mapout的本地文件集合。
6 synchronized (mapOutputFilesOnDisk) {
7 List<Path> mapFiles = new ArrayList<Path>();
8 long approxOutputSize = 0;
9 int bytesPerSum =
10 reduceTask.getConf().getInt("io.bytes.per.checksum", 512);
11 LOG.info(reduceTask.getTaskID() + "We have " +
12 mapOutputFilesOnDisk.size() + " map outputs on disk. " +
13 "Triggering merge of " + ioSortFactor + " files");
14 // 1. Prepare the list of files to be merged. This list is prepared
15 // using a list of map output files on disk. Currently we merge
16 // io.sort.factor files into 1.
17 //1. io.sort.factor构造List<Path> mapFiles,准备合并。 synchronized (mapOutputFilesOnDisk) {
18 for (int i = 0; i < ioSortFactor; ++i) {
19 FileStatus filestatus = mapOutputFilesOnDisk.first();
20 mapOutputFilesOnDisk.remove(filestatus);
21 mapFiles.add(filestatus.getPath());
22 approxOutputSize += filestatus.getLen();
23 }
24 }
25
26
27
28 // add the checksum length
29 approxOutputSize += ChecksumFileSystem
30 .getChecksumLength(approxOutputSize,
31 bytesPerSum);
32
33 // 2. 对list中的文件进行合并。
34 Path outputPath =
35 lDirAlloc.getLocalPathForWrite(mapFiles.get(0).toString(),
36 approxOutputSize, conf)
37 .suffix(".merged");
38 Writer writer =
39 new Writer(conf,rfs, outputPath,
40 conf.getMapOutputKeyClass(),
41 conf.getMapOutputValueClass(),
42 codec, null);
43 RawKeyValueIterator iter = null;
44 Path tmpDir = new Path(reduceTask.getTaskID().toString());
45 try {
46 iter = Merger.merge(conf, rfs,
47 conf.getMapOutputKeyClass(),
48 conf.getMapOutputValueClass(),
49 codec, mapFiles.toArray(new Path[mapFiles.size()]),
50 true, ioSortFactor, tmpDir,
51 conf.getOutputKeyComparator(), reporter,
52 spilledRecordsCounter, null);
53
54 Merger.writeFile(iter, writer, reporter, conf);
55 writer.close();
56 } catch (Exception e) {
57 localFileSys.delete(outputPath, true);
58 throw new IOException (StringUtils.stringifyException(e));
59 }
60
61 synchronized (mapOutputFilesOnDisk) {
62 addToMapOutputFilesOnDisk(localFileSys.getFileStatus(outputPath));
63 }
64 LOG.info(reduceTask.getTaskID() +
65 " Finished merging " + mapFiles.size() +
66 " map output files on disk of total-size " +
67 approxOutputSize + "." +
68 " Local output file is " + outputPath + " of size " +
69 localFileSys.getFileStatus(outputPath).getLen());
70 }
71 } catch (Throwable t) {
72 LOG.warn(reduceTask.getTaskID()
73 + " Merging of the local FS files threw an exception: "
74 + StringUtils.stringifyException(t));
75 if (mergeThrowable == null) {
76 mergeThrowable = t;
77 }
78 }
79 }
80}
9.InMemFSMergeThread线程的run方法。
1
2 public void run() {
3 LOG.info(reduceTask.getTaskID() + " Thread started: " + getName());
4 try {
5 boolean exit = false;
6 do {
7 exit = ramManager.waitForDataToMerge();
8 if (!exit) {
9 doInMemMerge();
10 }
11 } while (!exit);
12 } catch (Throwable t) {
13 LOG.warn(reduceTask.getTaskID() +
14 " Merge of the inmemory files threw an exception: "
15 + StringUtils.stringifyException(t));
16 ReduceCopier.this.mergeThrowable = t;
17 }
18 }
-
InMemFSMergeThread线程的doInMemMerge方法,
1private void doInMemMerge() throws IOException{ 2 if (mapOutputsFilesInMemory.size() == 0) { 3 return; 4 } 5 6 TaskID mapId = mapOutputsFilesInMemory.get(0).mapId; 7 8 List<Segment<K, V>> inMemorySegments = new ArrayList<Segment<K,V>>(); 9 long mergeOutputSize = createInMemorySegments(inMemorySegments, 0); 10 int noInMemorySegments = inMemorySegments.size(); 11 12 Path outputPath = mapOutputFile.getInputFileForWrite(mapId, 13 reduceTask.getTaskID(), mergeOutputSize); 14 15 Writer writer = 16 new Writer(conf, rfs, outputPath, 17 conf.getMapOutputKeyClass(), 18 conf.getMapOutputValueClass(), 19 codec, null); 20 21 RawKeyValueIterator rIter = null; 22 try { 23 LOG.info("Initiating in-memory merge with " + noInMemorySegments + 24 " segments..."); 25 26 rIter = Merger.merge(conf, rfs, 27 (Class<K>)conf.getMapOutputKeyClass(), 28 (Class<V>)conf.getMapOutputValueClass(), 29 inMemorySegments, inMemorySegments.size(), 30 new Path(reduceTask.getTaskID().toString()), 31 conf.getOutputKeyComparator(), reporter, 32 spilledRecordsCounter, null); 33 34 if (combinerRunner == null) { 35 Merger.writeFile(rIter, writer, reporter, conf); 36 } else { 37 combineCollector.setWriter(writer); 38 combinerRunner.combine(rIter, combineCollector); 39 } 40 writer.close(); 41 42 LOG.info(reduceTask.getTaskID() + 43 " Merge of the " + noInMemorySegments + 44 " files in-memory complete." + 45 " Local file is " + outputPath + " of size " + 46 localFileSys.getFileStatus(outputPath).getLen()); 47 } catch (Exception e) { 48 //make sure that we delete the ondisk file that we created 49 //earlier when we invoked cloneFileAttributes 50 localFileSys.delete(outputPath, true); 51 throw (IOException)new IOException 52 ("Intermediate merge failed").initCause(e); 53 } 54 55 // Note the output of the merge 56 FileStatus status = localFileSys.getFileStatus(outputPath); 57 synchronized (mapOutputFilesOnDisk) { 58 addToMapOutputFilesOnDisk(status); 59 } 60 } 61 }11.ReduceCopier.GetMapEventsThread线程的run方法。通过RPC询问TaskTracker,对每个完成的Event,获取maptask所在的服务器地址,即MapTask输出的地址,构造URL,加入到mapLocations,供copier线程获取。
1public void run() { 2 3 LOG.info(reduceTask.getTaskID() + " Thread started: " + getName()); 4 5 do { 6 try { 7 int numNewMaps = getMapCompletionEvents(); 8 if (numNewMaps > 0) { 9 LOG.info(reduceTask.getTaskID() + ": " + 10 "Got " + numNewMaps + " new map-outputs"); 11 } 12 Thread.sleep(SLEEP_TIME); 13 } 14 catch (InterruptedException e) { 15 LOG.warn(reduceTask.getTaskID() + 16 " GetMapEventsThread returning after an " + 17 " interrupted exception"); 18 return; 19 } 20 catch (Throwable t) { 21 LOG.warn(reduceTask.getTaskID() + 22 " GetMapEventsThread Ignoring exception : " + 23 StringUtils.stringifyException(t)); 24 } 25 } while (!exitGetMapEvents); 26 27 LOG.info("GetMapEventsThread exiting"); 28 29 }12.ReduceCopier.GetMapEventsThread线程的getMapCompletionEvents方法。通过RPC询问TaskTracker,对每个完成的Event,获取maptask所在的服务器地址,构造URL,加入到mapLocations。
1private int getMapCompletionEvents() throws IOException { 2 3 int numNewMaps = 0; 4 5 //RPC调用Tasktracker的getMapCompletionEvents方法,获得MapTaskCompletionEventsUpdate,进而获得TaskCompletionEvents 6 MapTaskCompletionEventsUpdate update = 7 umbilical.getMapCompletionEvents(reduceTask.getJobID(), 8 fromEventId.get(), 9 MAX_EVENTS_TO_FETCH, 10 reduceTask.getTaskID()); 11 TaskCompletionEvent events[] = update.getMapTaskCompletionEvents(); 12 13 // Check if the reset is required. 14 // Since there is no ordering of the task completion events at the 15 // reducer, the only option to sync with the new jobtracker is to reset 16 // the events index 17 if (update.shouldReset()) { 18 fromEventId.set(0); 19 obsoleteMapIds.clear(); // clear the obsolete map 20 mapLocations.clear(); // clear the map locations mapping 21 } 22 23 // Update the last seen event ID 24 fromEventId.set(fromEventId.get() + events.length); 25 26 // Process the TaskCompletionEvents: 27 // 1. Save the SUCCEEDED maps in knownOutputs to fetch the outputs. 28 // 2. Save the OBSOLETE/FAILED/KILLED maps in obsoleteOutputs to stop 29 // fetching from those maps. 30 // 3. Remove TIPFAILED maps from neededOutputs since we don't need their 31 // outputs at all. 32 //对每个完成的Event,获取maptask所在的服务器地址,构造URL,加入到mapLocations,供copier线程获取。 33 for (TaskCompletionEvent event : events) { 34 switch (event.getTaskStatus()) { 35 case SUCCEEDED: 36 { 37 URI u = URI.create(event.getTaskTrackerHttp()); 38 String host = u.getHost(); 39 TaskAttemptID taskId = event.getTaskAttemptId(); 40 int duration = event.getTaskRunTime(); 41 if (duration > maxMapRuntime) { 42 maxMapRuntime = duration; 43 // adjust max-fetch-retries based on max-map-run-time 44 maxFetchRetriesPerMap = Math.max(MIN_FETCH_RETRIES_PER_MAP, 45 getClosestPowerOf2((maxMapRuntime / BACKOFF_INIT) + 1)); 46 } 47 URL mapOutputLocation = new URL(event.getTaskTrackerHttp() + 48 "/mapOutput?job=" + taskId.getJobID() + 49 "&map=" + taskId + 50 "&reduce=" + getPartition()); 51 List<MapOutputLocation> loc = mapLocations.get(host); 52 if (loc == null) { 53 loc = Collections.synchronizedList 54 (new LinkedList<MapOutputLocation>()); 55 mapLocations.put(host, loc); 56 } 57 loc.add(new MapOutputLocation(taskId, host, mapOutputLocation)); 58 numNewMaps ++; 59 } 60 break; 61 case FAILED: 62 case KILLED: 63 case OBSOLETE: 64 { 65 obsoleteMapIds.add(event.getTaskAttemptId()); 66 LOG.info("Ignoring obsolete output of " + event.getTaskStatus() + 67 " map-task: '" + event.getTaskAttemptId() + "'"); 68 } 69 break; 70 case TIPFAILED: 71 { 72 copiedMapOutputs.add(event.getTaskAttemptId().getTaskID()); 73 LOG.info("Ignoring output of failed map TIP: '" + 74 event.getTaskAttemptId() + "'"); 75 } 76 break; 77 } 78 } 79 return numNewMaps; 80 } 81} 82}
13.ReduceTask.ReduceCopier的createKVIterator方法,从拷贝到的map输出创建RawKeyValueIterator,作为reduce的输入。
1private RawKeyValueIterator createKVIterator(
2 JobConf job, FileSystem fs, Reporter reporter) throws IOException {
3
4 // merge config params
5 Class<K> keyClass = (Class<K>)job.getMapOutputKeyClass();
6 Class<V> valueClass = (Class<V>)job.getMapOutputValueClass();
7 boolean keepInputs = job.getKeepFailedTaskFiles();
8 final Path tmpDir = new Path(getTaskID().toString());
9 final RawComparator<K> comparator =
10 (RawComparator<K>)job.getOutputKeyComparator();
11
12 // segments required to vacate memory
13 List<Segment<K,V>> memDiskSegments = new ArrayList<Segment<K,V>>();
14 long inMemToDiskBytes = 0;
15 if (mapOutputsFilesInMemory.size() > 0) {
16 TaskID mapId = mapOutputsFilesInMemory.get(0).mapId;
17 inMemToDiskBytes = createInMemorySegments(memDiskSegments,
18 maxInMemReduce);
19 final int numMemDiskSegments = memDiskSegments.size();
20 if (numMemDiskSegments > 0 &&
21 ioSortFactor > mapOutputFilesOnDisk.size()) {
22 // must spill to disk, but can't retain in-mem for intermediate merge
23 final Path outputPath = mapOutputFile.getInputFileForWrite(mapId,
24 reduceTask.getTaskID(), inMemToDiskBytes);
25 final RawKeyValueIterator rIter = Merger.merge(job, fs,
26 keyClass, valueClass, memDiskSegments, numMemDiskSegments,
27 tmpDir, comparator, reporter, spilledRecordsCounter, null);
28 final Writer writer = new Writer(job, fs, outputPath,
29 keyClass, valueClass, codec, null);
30 try {
31 Merger.writeFile(rIter, writer, reporter, job);
32 addToMapOutputFilesOnDisk(fs.getFileStatus(outputPath));
33 } catch (Exception e) {
34 if (null != outputPath) {
35 fs.delete(outputPath, true);
36 }
37 throw new IOException("Final merge failed", e);
38 } finally {
39 if (null != writer) {
40 writer.close();
41 }
42 }
43 LOG.info("Merged " + numMemDiskSegments + " segments, " +
44 inMemToDiskBytes + " bytes to disk to satisfy " +
45 "reduce memory limit");
46 inMemToDiskBytes = 0;
47 memDiskSegments.clear();
48 } else if (inMemToDiskBytes != 0) {
49 LOG.info("Keeping " + numMemDiskSegments + " segments, " +
50 inMemToDiskBytes + " bytes in memory for " +
51 "intermediate, on-disk merge");
52 }
53 }
54
55 // segments on disk
56 List<Segment<K,V>> diskSegments = new ArrayList<Segment<K,V>>();
57 long onDiskBytes = inMemToDiskBytes;
58 Path[] onDisk = getMapFiles(fs, false);
59 for (Path file : onDisk) {
60 onDiskBytes += fs.getFileStatus(file).getLen();
61 diskSegments.add(new Segment<K, V>(job, fs, file, codec, keepInputs));
62 }
63 LOG.info("Merging " + onDisk.length + " files, " +
64 onDiskBytes + " bytes from disk");
65 Collections.sort(diskSegments, new Comparator<Segment<K,V>>() {
66 public int compare(Segment<K, V> o1, Segment<K, V> o2) {
67 if (o1.getLength() == o2.getLength()) {
68 return 0;
69 }
70 return o1.getLength() < o2.getLength() ? -1 : 1;
71 }
72 });
73
74 // build final list of segments from merged backed by disk + in-mem
75 List<Segment<K,V>> finalSegments = new ArrayList<Segment<K,V>>();
76 long inMemBytes = createInMemorySegments(finalSegments, 0);
77 LOG.info("Merging " + finalSegments.size() + " segments, " +
78 inMemBytes + " bytes from memory into reduce");
79 if (0 != onDiskBytes) {
80 final int numInMemSegments = memDiskSegments.size();
81 diskSegments.addAll(0, memDiskSegments);
82 memDiskSegments.clear();
83 RawKeyValueIterator diskMerge = Merger.merge(
84 job, fs, keyClass, valueClass, diskSegments,
85 ioSortFactor, numInMemSegments, tmpDir, comparator,
86 reporter, false, spilledRecordsCounter, null);
87 diskSegments.clear();
88 if (0 == finalSegments.size()) {
89 return diskMerge;
90 }
91 finalSegments.add(new Segment<K,V>(
92 new RawKVIteratorReader(diskMerge, onDiskBytes), true));
93 }
94 return Merger.merge(job, fs, keyClass, valueClass,
95 finalSegments, finalSegments.size(), tmpDir,
96 comparator, reporter, spilledRecordsCounter, null);
97 }
14.ReduceTask的runNewReducer方法。根据配置构造reducer以及其运行的上下文,调用reducer的reduce方法。
1@SuppressWarnings("unchecked")
2 private <INKEY,INVALUE,OUTKEY,OUTVALUE>
3 void runNewReducer(JobConf job,
4 final TaskUmbilicalProtocol umbilical,
5 final TaskReporter reporter,
6 RawKeyValueIterator rIter,
7 RawComparator<INKEY> comparator,
8 Class<INKEY> keyClass,
9 Class<INVALUE> valueClass
10 ) throws IOException,InterruptedException,
11 ClassNotFoundException {
12 //1. 构造TaskContext
13 org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
14 new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
15 //2. 根据配置的Reducer类构造一个Reducer实例
16 org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer = (org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
17 ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
18 //3. 构造RecordWriter
19 org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> output =
20 (org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE>)
21 outputFormat.getRecordWriter(taskContext);
22 job.setBoolean("mapred.skip.on", isSkipping());
23
24 //4. 构造Context,是Reducer运行的上下文
25 org.apache.hadoop.mapreduce.Reducer.Context
26 reducerContext = createReduceContext(reducer, job, getTaskID(),
27 rIter, reduceInputValueCounter,
28 output, committer,
29 reporter, comparator, keyClass,
30 valueClass);
31 reducer.run(reducerContext);
32 output.close(reducerContext);
33 }
15.抽象类Reducer的run方法。从上下文中取出一个key和该key对应的Value集合(Iterable
1public void run(Context context) throws IOException, InterruptedException {
2 setup(context);
3 while (context.nextKey()) {
4 reduce(context.getCurrentKey(), context.getValues(), context);
5 }
6 cleanup(context);
7 }
16.Reducer类的reduce,是用户一般会覆盖来执行reduce处理逻辑的方法。
1@SuppressWarnings("unchecked")
2 protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
3 ) throws IOException, InterruptedException {
4 for(VALUEIN value: values) {
5 context.write((KEYOUT) key, (VALUEOUT) value);
6 }
完。