最佳实践:Karmda和Istio提高分布式云的负载与流量韧性
记录在2024年8月21日在香港Kubecon上发表的技术演讲《Best Practice: Karmada & Istio Improve Workload & Traffic Resilience of Production Distributed Cloud》

大家好,我是张超盟,来自华为云 ,我今天带来的是一个有关服务韧性的话题。将介绍在分布式云场景下,Karmada和Istio相互配合,管理多K8s集群的负载和流量,改善服务韧性的实践。

我是华为云分布式云原生的架构师,在过去的近十年里在华为云从事云原生相关的设计开发工作,包括过去几年里一直负责华为云应用服务网格产品。

演讲的内容包括:韧性的背景,K8s和Istio作为云原生领域的基座技术,能力很丰富也很强大,我们从韧性角度简单审视下相关能力。然后介绍分布式云如何改善单云的韧性,又引入了哪些新的挑战。 重点是实践的内容,介绍在分布式云环境下:Karmada如何提高多集群的负载韧性,Istio如何提高多集群的流量韧性;以及Karmada和Istio相互配合提供完整的多集群应用韧性的最佳实践。

简单讲,韧性描述了这样一种能力,系统在过载、故障或在遭受攻击的时候还能够完成基本功能。韧性告诉我们,①虽然我们不想要失败,但是我们得承认失败总是会发生。因而我们需要为失败而设计系统,减少故障对系统的影响。有个著名的说法,韧性不能保证你多挣到钱,但是可以保证你少赔钱。竞争力可能决定产品的上线,韧性才能保证产品的下线。韧性应用于工程世界的所有系统。计算机世界里韧性是系统设计需要考虑的关键因素。
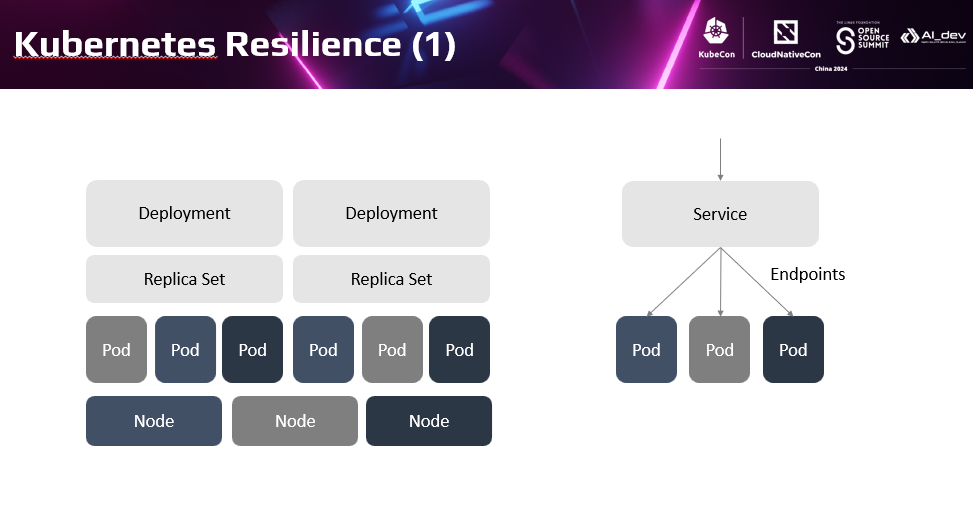
下面简单看下K8s和Istio提供的韧性能力。K8s大家都非常熟悉,K8s提供了Deployment,Replica Set和Service三个核心对象。 Deployment和Replica Set声明式控制负载实例的副本数和配置。 Service让为每个服务器提供了统一的访问入口,自动在多个实例间负载均衡。k8s基于这三种关键机制实现了应用部署、升级、访问的自动化。较之传统虚拟机方式,除了带来了轻量、敏捷、弹性的特点外,同时也提供了丰富的平台能力,提高应用的韧性。
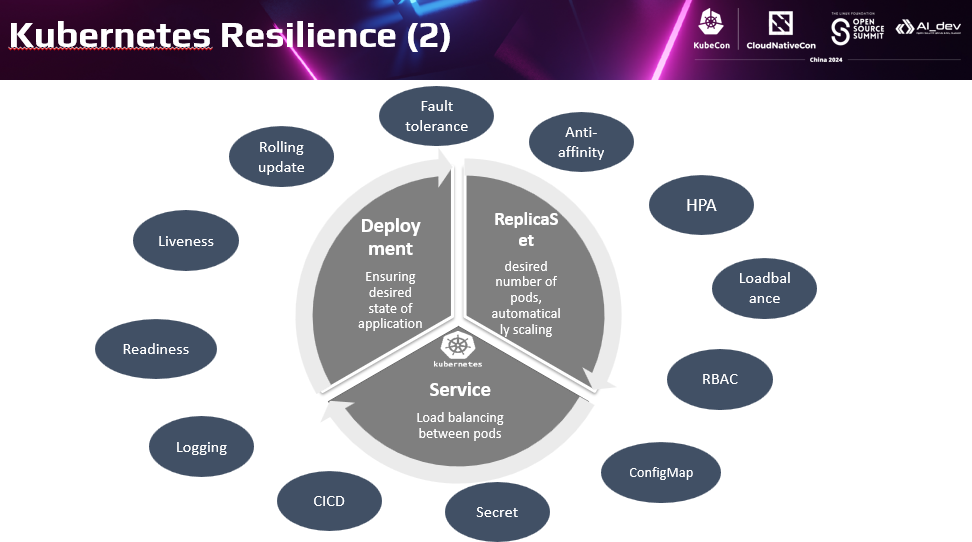
我们尝试通过韧性角度认识下这些我们熟悉的能力。首先K8s自动控制负载实例数,通过多实例提供冗余容错能力,提高可用性。特别是提供了节点、AZ的反亲和部署,保证局部资源故障时服务总体仍然可用。另外滚动升级,交替创建新Pod、停止老Pod。通过平滑升级减少了升级的停机时间。水平扩缩容 HPA快速自动弹性扩缩容实例,避免了业务量大资源不足导致的系统过载。Liveness和Readiness的健康检查,实现应用故障自动检测和自愈。
此外k8s还提供了其他能力,间接改善韧性。如: 提供RBAC,保护应用和数据的安全。内置的日志、事件和监控,通过平台方式提供了应用运维和Troubleshooting的关键能力。ConfigMap和Secret,方便用户把配置从代码中独立处理,避免了重新部署带来的变更风险。CICD,对接流水线自动化提高上线变更效率,也减小了人工风险。
可以看到大量我们平时用到并且非常熟悉的k8s能力,都是基于韧性目标设计的。
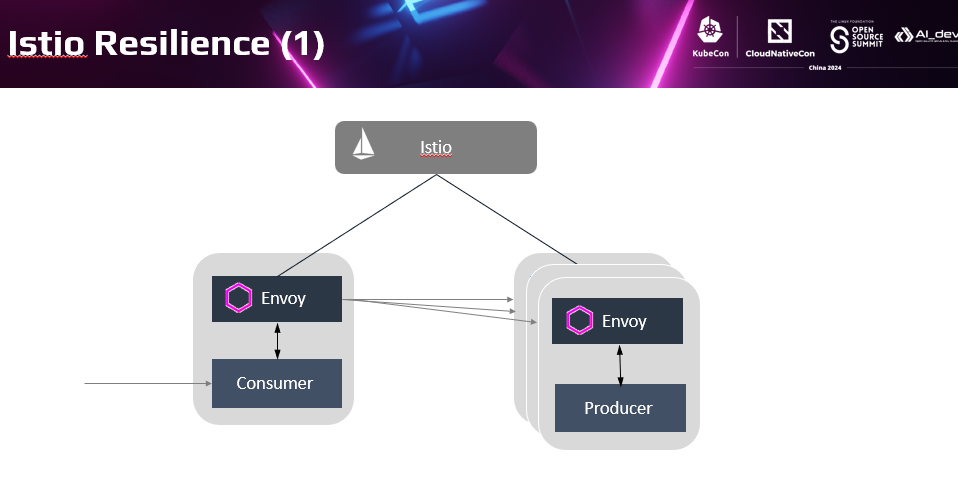
Istio的机制大家也比较熟悉,通过透明代理拦截流量,代替应用执行流量动作,从而以非侵入方式提供了七层的流量能力。.Istio提供的能力非常丰富,这里我们也同样从韧性的视角审视Istio提供的众多能力。可能会发现原来我们经常用到的Istio能力很多都和韧性相关。

我们都说Istio在k8s基础设能力之上,提供了面向应用的上层能力增强,这种增强的配合关系同样适用于韧性方面。Istio提供的不只是四层负载均衡,而是基于七层的流量提供了更多的能力。包括:访问亲和性、故障倒换等能力。通过自动重试提高访问成功率;通过限流防止系统过载。基于七层流量特征的灰度分流策略,在不同版本间分配流量,降低版本升级引起的风险。不同于k8s的的Readiness,Istio提供了基于熔断器的故障隔离和故障恢复能力。 另外非侵入的调用链、访问日志,跟踪服务间调用细节,方便故障定位定界。通过非侵入故障注入,提前发现产品缺陷。可以看到,Istio以非侵入方式提供了大量面向应用的韧性。
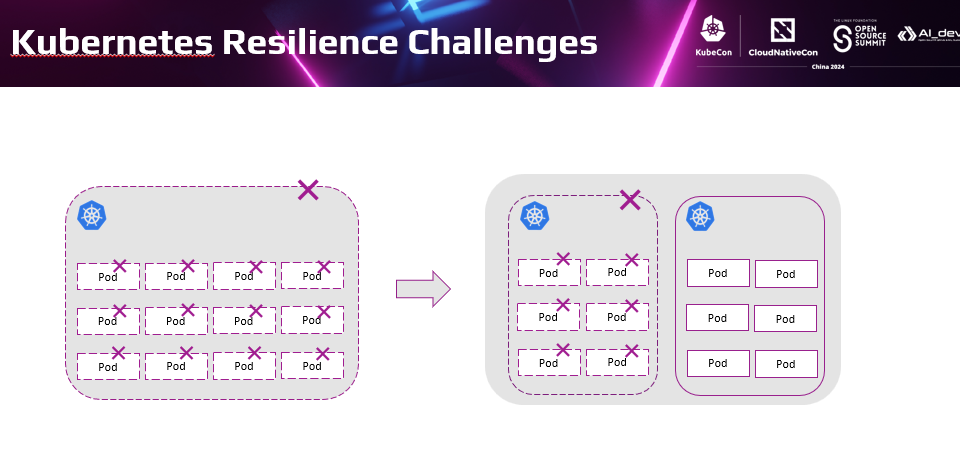
如前面总结Kubernetes提供了负载多实例,并支持基于节点、AZ的反亲和部署提高应用韧性。但这些能力仅局限于一个Kubernetes集群内部,不能在更大范围提供应用的韧性。这样对于Kubernetes集群自身的故障无能为力。当客户业务都集中在一个集群时,集群异常引发了全局的业务断服宕机。生产中这种事故频繁发生在集群升级时。
这种现象的根本原因是故障半径的问题。就像把所有的鸡蛋放在一个篮子里,一旦篮子有问题,没有一个鸡蛋能幸存下来。解决这类问题直观的思路就是减小故障半径,把鸡蛋分开放到多个篮子里。
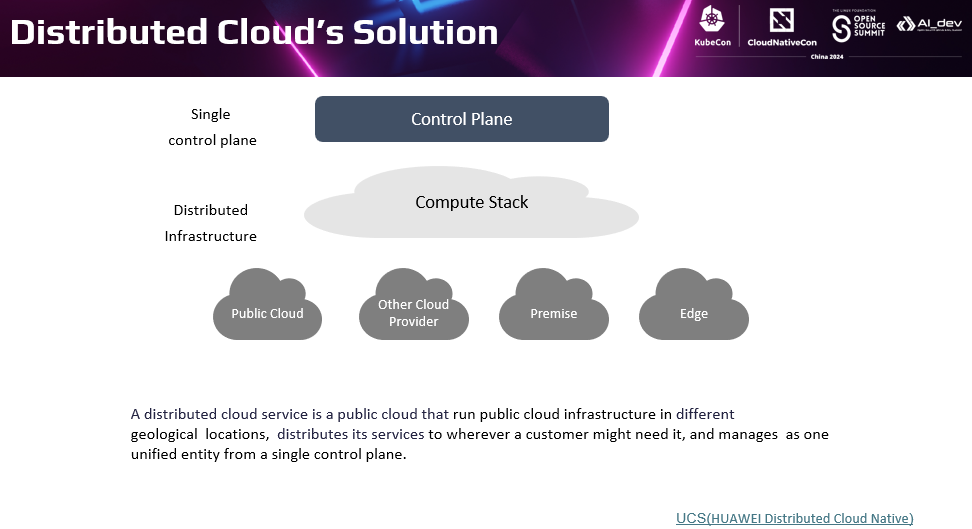
有一种分布式云的架构可以在一定程度上解决这个问题。
分布式云是一种基础设施架构;可以在多个物理位置,包括公有云自己的数据中心、其他云提供商的数据中心、用户本地或者第三方数据中心、边缘,运行公有云的基础设施。并且从单个控制平面统一管理这些云资源。
对于云原生场景的分布式云,我们称为分布式云原生。华为云分布式云原生服务UCS,将云原生基础设施分发到各种物理位置,使得用户可以在业务期望的任意位置运行云原生应用,并且通过公有云上集中的云原生控制面统一管理。

可以看到,较之单云架构,分布式云提供的优势包括:
- 分布式部署的数据和应用可以更接近用户,使得响应时间更短。Less latency, closer to end users.
- 数据和应用可以限定在规定的范围内,更容易满足合规性要求。Increased regulatory compliance
- 可以结合分布式的资源快速构建业务,扩展性更强 Better scalability
- 此外还可以通过统一的控制台,监控运维分布式环境部署的应用。Improved visibility
当然我们关注的韧性改善也包括在内。天然分布式环境部署,提供了冗余和容错,一个地域或者某个云环境故障,其他环境的可以故障倒换,接管业务。
当然,分布式云也引入了众多挑战:
- 复杂性(Complexity):管理地理上可能跨越多个云提供商和本地数据中心分散的云资源,会带来新的复杂性。
- 安全性(Security):在分布式环境中,保护数据和应用程序安全会更加困难。
- 异质性(Heterogeneity):分布式云环境通常涉及不同硬件、软件、操作系统和云提供商的服务。
- 延时(Latency and Network Performance)分布式云在某些情况下有助于减少延迟,但如果使用不当,会引入新的网络延时
在云原生场景下,k8s本身定义了标准统一的接口,一定程度简化了其中复杂性和异构资源问题。.但是如何将分布式在不同物理位置,不同的k8s管理起来,并且提供和单个k8s集群类似的体验,还是有很大的挑战。Karmada可能是一个答案。
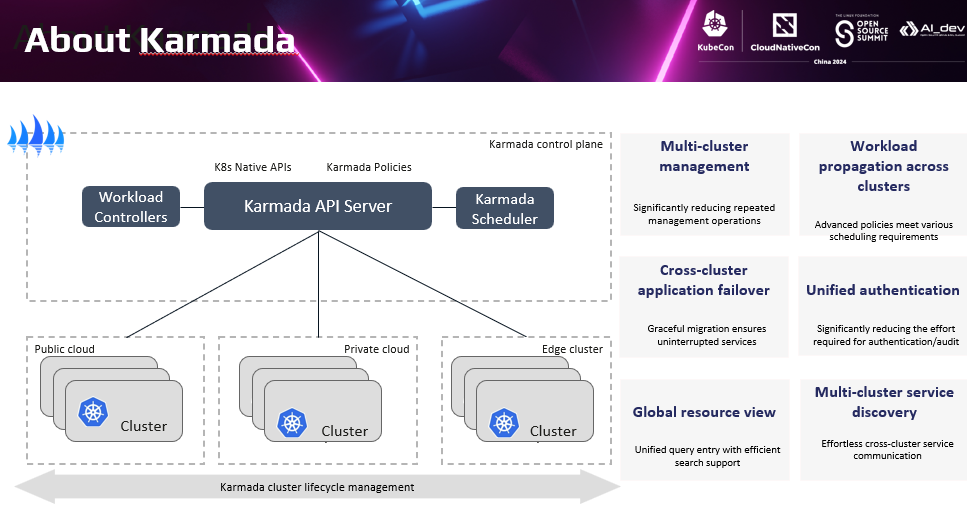
简单介绍下Karmada。Karmada的设计目标,是使开发人员能够像使用单个 Kubernetes 集群一样使用多集群能力,管理跨集群的资源;对用户提供一个可以不断扩展的容器资源池;并通过多集群方式进一步提高云原生应用的韧性。
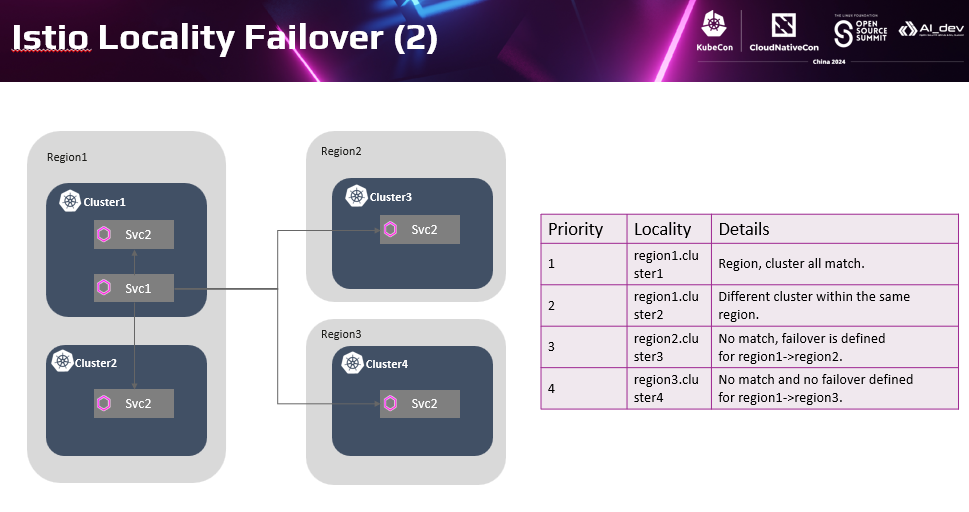
这里简单列举了Karmada提供的关键功能。包括:多集群管理、跨集群负载分发、全局资源视图、多集群服务发现等。 我们重点关注两个与今天分享主题密切相关的特征: 一个是Karmada怎样解决前面讲到的分布式云的管理复杂性问题。另外一个是Karmada的分布式云多集群管理,具体怎么实践多集群韧性目标的。
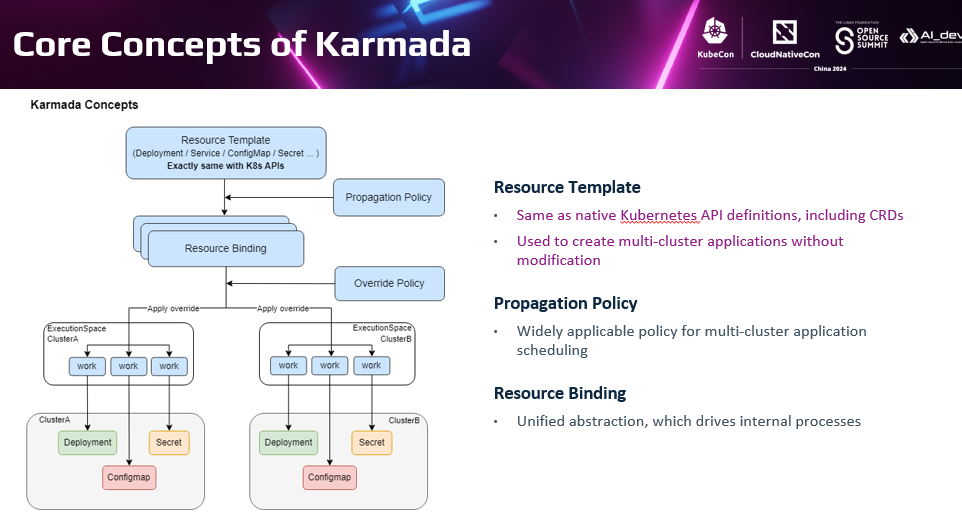
首先第一点:Karmada提供了集中式的控制面;这与分布式云的模型定义也完全一致。 用户无需连接甚至感知分布式环境部署了多少个集群。只需要通过集中的入口即可。
更重要的是,Karmada使用和单集群完全兼容的API管理多集群资源,这和之前的KubeFed相关API有极大的不同。Karmada的资源模板是原始的Kubernetes单集群的资源模板,配套多集群分发策略Propagation Policy的就可以变成多集群对象。用户在多集群的管理入口上,配置单集群完全兼容的资源对象,Karmada控制器根据分发策略会自动控制在多个集群上资源创建、更新对应资源。
对用户来说访问多集群的Kube-apiserver就跟单集群一样。极大的简化了用户的管理分布式环境下多个集群资源的复杂性。
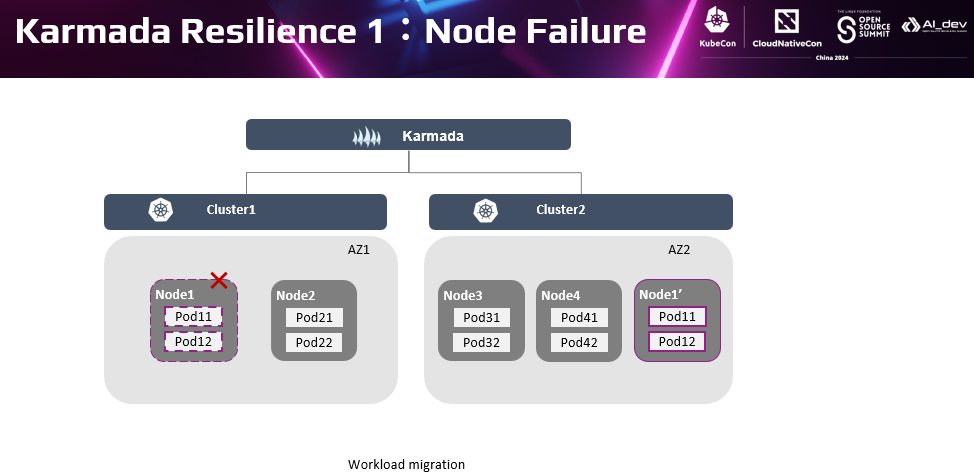
另外一点,多集群韧性。从前面分布式云的概念模型分析了解到,分布式云通过分布式环境的冗余和容错提供了更高的服务韧性。Karmada在韧性这个方向上提供了更丰富的能力。首先当某个节点发生故障,导致该节点上的负载实例不可用。除了和单集群一样在当前集群内重建对应负载实例,Karmada可以根据多集群应用迁移策略,在其他集群中重建出对应的负载实例。如这里当Cluster1的Node11故障时,并且Cluster1中没有可用的节点资源运行这些Pod时,Karmada可以控制在Cluster2上自动创建这些Pod。当负载迁移模式配置为优雅模式(Graciously)时,Karmada会等待负载在新集群上恢复健康,或者在一定时间后才驱逐原集群上的应用。使得故障迁移过程平滑且优雅。
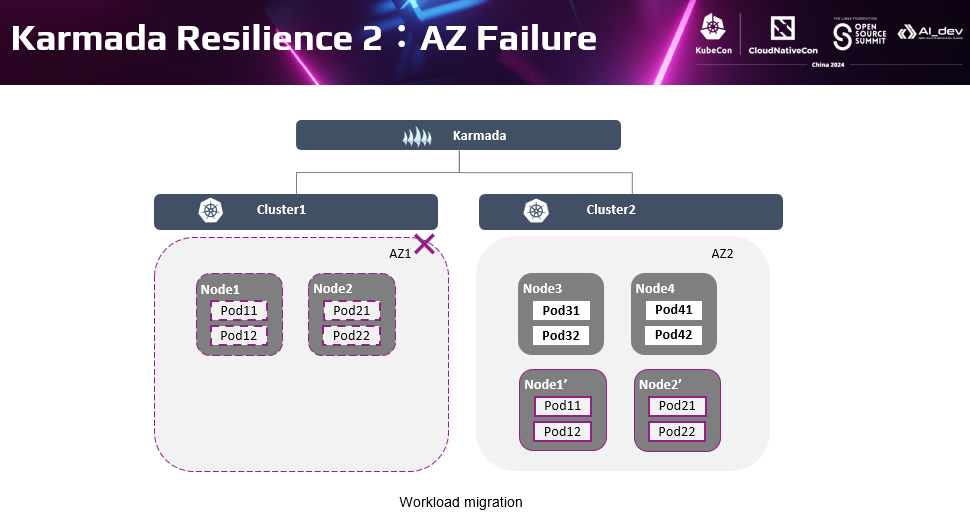
同样的,对于AZ级别的可用性保证,不仅可以应用单集群的AZ间反亲和部署。也可以应用Karmada的多集群管理,将故障AZ的节点上的实例自动迁移到本集群或其他集群的节点上。如这里AZ1整体故障后,Karmada的负载迁移策略可以自动将负载迁移到另外一个集群的AZ2的节点上。多集群的AZ高可用应用可以是每个集群多个AZ,或固定每个集群一个AZ。在实践中,我们的客户应用Karmda做多集群管理时,为了管理简单,一般每个集群会对应一个AZ。
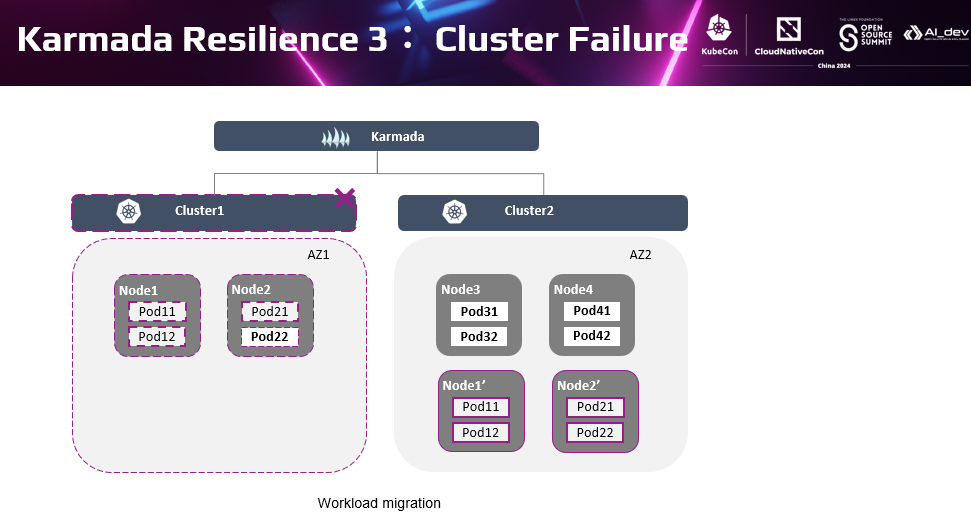
以上两种节点级和AZ级故障的可用性是单集群也具备的能力,应对整个集群故障才是Karmada的差异化优势。当检测到某个集群故障时,集群上的负载Pod将会被驱逐。基于副本调度策略,Karmada动态地将负载实例从故障集群迁移到另外一个可用集群。具体是集群判定为不健康时,自动添加污点。当检测到故障群集群不在被副本分发策略容忍时**,**该集群将从可调度资源中删除,随后Karmada调度器将重新调度相关负载,即分发到其他集群中。
除了集群自动的健康判定外,Karmada也支持用户根据自身对业务的需求管理集群。如当用户不希望在某个集群上继续运行工作负载时,可以添加上污点标记集群为不可用。将一个集群的负载整体隔离掉,快速高效地进行故障隔离,最大限度保证业务总体可用性。
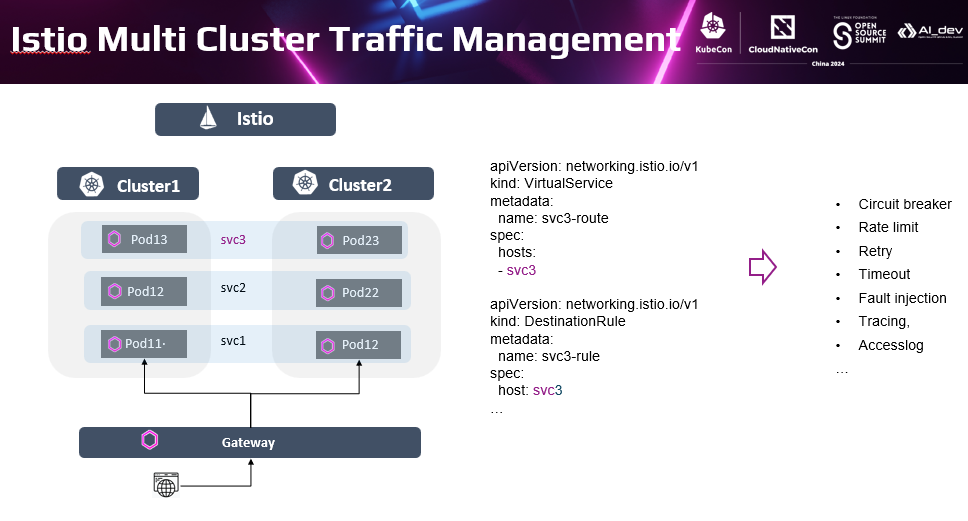
下面关注下Istio韧性能力在多集群中的应用。前面介绍过istio提供了熔断、限流、重试、超时、故障注入等韧性能力。在多集群视图下,和单集群的差别是Istio管理的服务的实例跨集群。服务逻辑视图并没有改变,流量策略的作用对象仍然是策略描述的那个服务,因此内容也没有大的改变,能力也没有差别。非要说差别只是场景有所侧重。
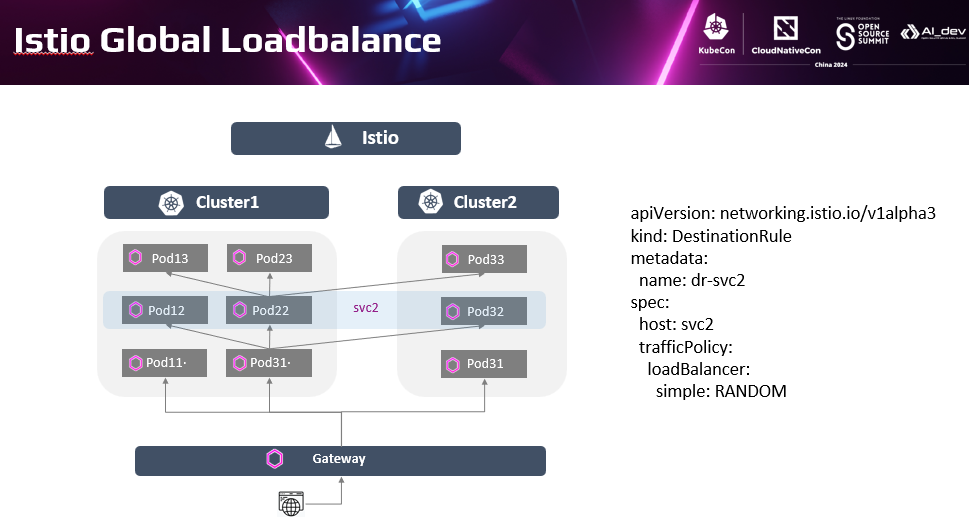
最典型的侧重场景是跨集群的流量管理。当目标服务的服务实例跨了不同的集群,可以通过Istio控制到不同集群的服务实例上的流量。.默认在不特殊配置时,会执行全局负载均1最典型的侧重场景是跨集群的流量管理。当目标服务的服务实例跨了不同的集群,可以通过Istio控制到不同集群的服务实例上的流量。
默认在不特殊配置时,会执行全局负载均衡。即当访问目标服务时,网格数据面会执行全局的负载均衡策略,在跨集群的后端实例间均衡地分发流量;这里的流量来源可以是来自Gateway的南北向流量,也可以是服务间Sidecar控制的东西向流量。
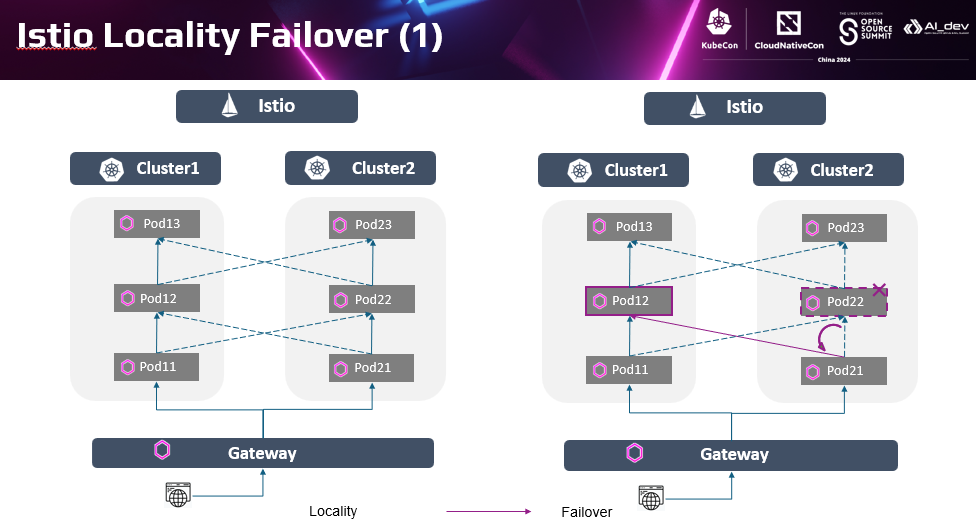
在Istio管理分布式应用的场景中,更典型的是在全局的负载均衡的基础上,基于服务实例位置进行亲和性访问和故障倒换。优先访问与源服务亲和的目标服务实例,如优先访问本集群内的服务实例。这也是生产中最常应用的方式,流量在每个集群内闭环,保证了服务间的访问效率。当本集群实例不可用时,会自动倒换流量到其他集群的服务实例上。Cluster2的Pod22不可用时,Istio会控制自动到换到Cluster1的Pod21实例上。
在Istio管理分布式应用的场景中,更典型的是在全局的负载均衡的基础上,基于服务实例位置进行亲和性访问和故障倒换。优先访问与源服务亲和的目标服务实例,如优先访问本集群内的服务实例。这也是生产中最常应用的方式,流量在每个集群内闭环,保证了服务间的访问效率。当本集群实例不可用时,会自动倒换流量到其他集群的服务实例上。Cluster2的Pod22不可用时,Istio会控制自动到换到Cluster1的Pod21实例上。

可以看到Isito和Karmada分别提供了丰富强大的功能保证多集群上运行的服务的韧性。二者配合在一些典型的场景下能提供更全面、更贴近用户使用要求的韧性能力。如前面提到的k8s集群升级问题,可以通过Karmada和Istio配合进行集群灰度升级。
首先,可以选择一个待升级的集群作为灰度环境。配置Istio流量策略将全部流量切换到另一个集群;配置Karmada资源分发策略讲集群资源迁移到另外一个集群。对灰度集群执行升级,并观察各个组件的正常运行正常。修改Karmada资源分发策略将部分负载迁移到灰度集群,观察负载在灰度环境上正常运行。配置Istio流量策略将少量流量切换至灰度集群,从最终业务视角观察服务被访问后正常响应。 完成一个灰度集群的升级。
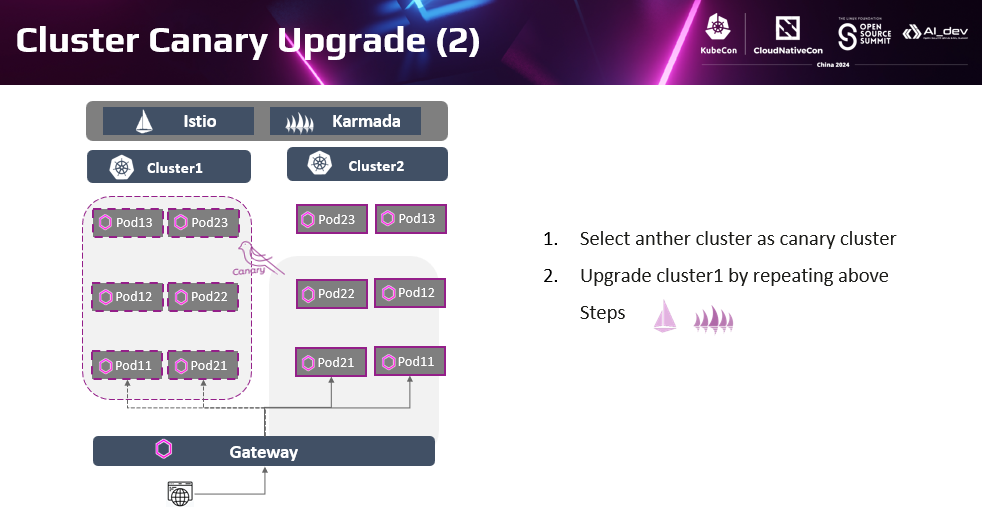
当灰度集群业务工作正常后,将另外一个集群当成灰度集群,重复前面的过程。即基于Karmada跨集群负载迁移策略将负载迁移到对端集群。基于Istio流量策略将流量都切分到另外一个集群。直至完成两个集群升级。

在两个集群都升级完成后,更新Karmada的资源分发策略,恢复在原有的两个集群上部署资源。通过Istio流量策略控制在集群的服务实例上进行全局负载均衡。在升级的整个过程中,不管灰度集群的升级过程怎么用,用户总是可以访问到可用的目标服务后端,甚至在升级过程中提供服务的后端实例个数也没有减少。如果出现集群升级问题,只需立即修复灰度集群,而不会影响最终用户的业务。通过这种集群灰度升级的方式,确保升级过程中出现的集群问题问题不会对用户业务造成影响,从而保证了业务总体韧性。
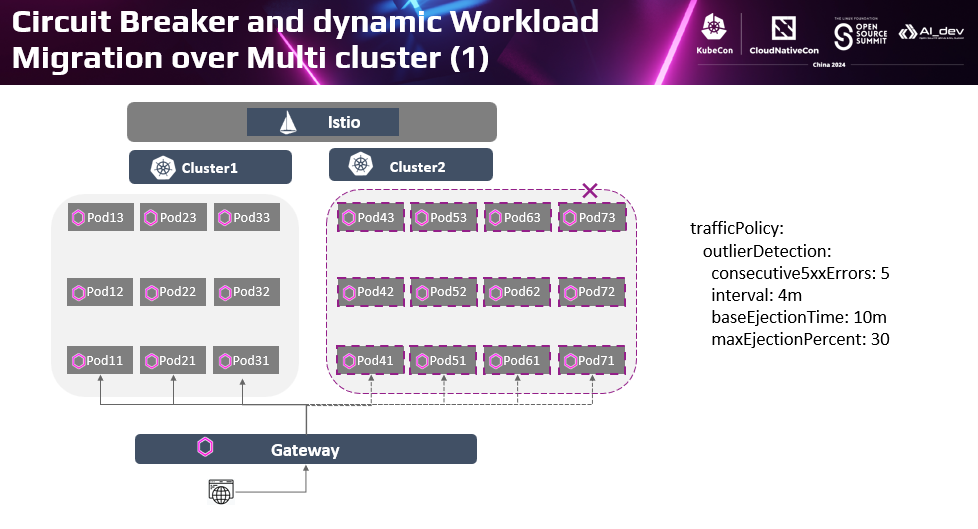
除了灰度这种主动控制流量和负载的在集群间分发的场景外,在故障过程中,Istio和Karmada相互配合,提供更优的跨集群应用韧性。 如前面介绍的Istio多集群服务熔断的场景。当某个集群故障时,Istio熔断策略可以自动隔离该集群上服务的后端,将流量分发到其他集群上。
这种方式虽然可以隔离故障实例,提高服务访问成功率。但是当部分认定为故障的实例被隔离后,实际提供服务的实例数就会比规划的实例数少。特别是当故障集群的实例数较多时,如本来有7个实例,集群1和集群2分别部署了3个和4个实例,当集群2故障时,4个实例被隔离,只有3个实例供服务。当客户端还是以原有负荷访问时,很容易导致剩下的实例过载。Isito的熔断策略中有一个配置,当判定故障的实例数超过一定比例,会放弃执行隔离动作,在这个例子里就是4个不健康的实例加3个健康的实例也好过只有3个健康的实例。
很容易发现这种策略背后有一种万不得已的异味,以牺牲服务访问质量为代价的方案很多时候也并不是用户想要的。有没有办法能兼顾呢?

在多集群场景下,配合Karmada的跨集群负载迁移策略,可以提供不一样的能力。。还是在刚才故障场景下,当Cluster2故障时。基于Istio的熔断策略隔离Cluster2上的4个故障实例。同时Karmada的跨集群负载分发策略,可以将Cluster2上四个实例在Cluster1中重新创建,从而保证服务的实例数保持在规划的7个实例的目标。访问服务的流量会在集群1的7个实例上负载均衡。即通过Istio的熔断机制保证满足服务访问成功率的同时,通过Karmada的跨集群负载分发策略保证了服务的容量没有折损,从而全面保证了应用的韧性。

以上是今天分享的全部内容,但只是我们在生产中解决的部分问题。我就将继续努力,在UCS中以云平台的方式保证应用韧性,帮助用户守护好业务下限,用户可以专注构建竞争力,不断冲击业务上限,从而取得商业成功。
谢谢大家。